Dividir para conquistar#
A frase latina “Divide et impera” é tão antiga quanto a política e a guerra. A abordagem de dividir seu inimigo para que você possa reinar é atribuída a Júlio César - ele a aplicou com sucesso para conquistar a Gália vinte e dois séculos atrás. Mas ele não foi o primeiro, nem o último, a utilizá-la.
Qualquer sistema, quando dividido, é muito mais tratável do que o todo. Napoleão Bonaparte sabia disso: uma de suas táticas favoritas era enviar todo o seu exército contra uma fração do exército inimigo e, dessa forma, desgastar lentamente o que antes era uma força formidável. Tendo dividido o inimigo em pedaços pequenos e manejáveis, a conquista de Napoleão estava garantida (The Napoleon Method: Divide and Conquer).
Os método de Júlio Cesar e Napoleão Bonaparte são amplamente aplicados em computação. Como foi mencionado o problema de ordenação de uma lista é bastante simples e ideal para explorarmos um rico universo de ideias e soluções diferentes. Chegou a vez de dividir para conquistar.
Objetivos de aprendizagem#
Nosso foco será na estratégia algorítmica de dividir para conquistar em que um problema é dividido recursivamente em dois ou mais subproblemas do mesmo tipo ou de tipos relacionados, até que eles se tornem simples o suficiente para serem resolvidos diretamente. As soluções para os subproblemas são então combinadas para obtermos uma solução para o problema original.
Já aplicamos essa técnica em algumas funções recursivas que fizemos. O problema que continuaremos a tratar é o de ordenar uma lista de elementos. Mas mantenha em mente que nosso objetivo não é apenas “obter uma lista ordenada”, mas estudar e entender algoritmos que usam a técnica de dividir para conquistar usando esse rico contexto de aplicação.
Dizemos que uma lista \(\mathtt{v[0:n]}\) é crescente se
Como temos feito nos exemplos, as listas serão de objetos int mas elas poderiam ser de str ou de quaisquer outros objetos que possam atuar como operandos de operadores relacionais como <, <=, > ou >=.
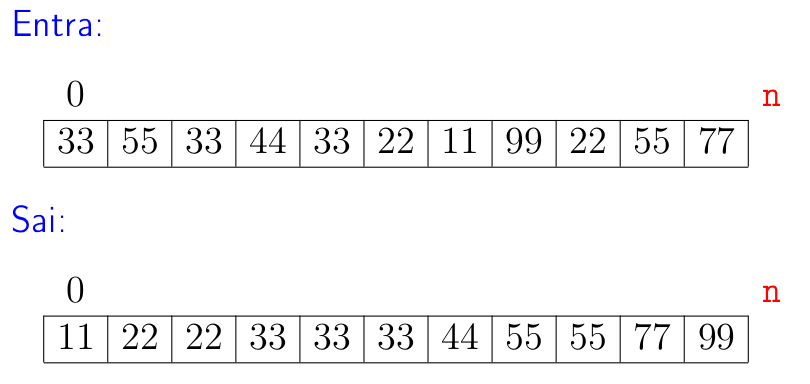
Problema: Rearranjar os elementos de uma lista
v[0:n]de modo que ela fique crescente.
Intercalação de listas#
Começaremos considerando o subproblema que fará parte da fase de combinar da estratégia de dividir para conquistar. Esse ainda não é exatamente o subproblema que utilizaremos na fase combinar, mas será útil para irmos aquecendo nossos motores. 🙂
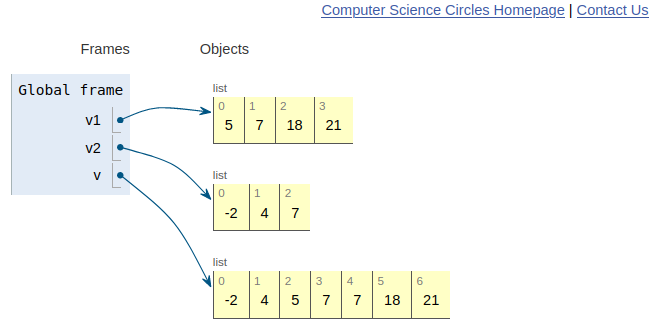
Problema da intercalação de listas: Dadas duas listas crescentes
v1ev2, criar uma nova lista crescentevformada pelos elementos dev1ev2.
Suporemos que v1 tem m elementos e v2 tem n elementos.
Diremos que a lista v é o resultado da combinação ou intercalação de v1 e v2.
Por exemplo, se
v1 = [5, 7, 18, 21] e
v2 = [-2, 4, 7]
devemos obter
v = [-2, 4, 5, 7, 7, 18, 21]
🤔 É claro que esse problema é bem simples e que para resolvê-lo poderíamos meramente fazer
1 v = v1 + v2
2 shakersort(v)
O problema dessa estratégia ingênua é o seu consumo de tempo. 👎🏽 Estamos em um momento que para nós não interessa apenas que “funcione”. Que os programas que funcionam nos desculpem, mas eficiência é fundamental! 🥇
O consumo de tempo da linha 1 é proporcional a \(\mathtt{n+m = \textup{O}(m+n)}\) e o consumo de tempo da linha 2, no pior caso, é \(\mathtt{\textup{O}((m+n)^2)}\).
Isso significa que para intercalarmos duas listas com \(\mathtt{2(n+m)}\) elementos poderemos gastar quatro vezes mais tempo do que o tempo gasto para intercalarmos v1 e v2.
A propósito, em caso de dúvida sobre o consumo de tempo assintótico das funções e métodos nativos do Python e que usaremos consulte a página TimeComplexity.
Essa primeira tentativa não usou em absolutamente nada o fato de v1 e v2 serem crescentes.
Veremos como fazer o mesmo trabalho das linhas 1 e 2 gastando tempo total proporcional a \(\mathtt{n+m}\) usando a ordem de v1 e v2.
Na prática isso quer dizer que para intercalarmos duas listas com \(\mathtt{2(n+m)}\) elementos poderemos gastar o dobro do tempo do que gasto para intercalarmos v1 e v2 e
não o quadruplo do tempo. 👍🏿
A função merge_lsts() a seguir resolve o problema da intercalação.
A numeração das linhas não faz parte da solução e serve para referenciá-las mais adiante.
def merge_lsts(v1, v2):
''' (list, list) -> list
RECEBE duas listas crecentes v1 e v2.
RETORNA uma nova lista v crescente com todos os elementos de v1 e v2.
'''
0 v = []
1 m, n = len(v1), len(v2)
2 i = j = 0
3 while i < m and j < n:
4 if v1[i] < v2[j]:
5 v.append(v1[i])
6 i += 1
else:
7 v.append(v2[j])
8 j += 1
# copie os elementos que sobraram em v1
9 v += v1[i:m]
# copie os elementos que sobraram em v2
10 v += v2[j:n]
11 return v
Antes de continuar talvez valha a pena assistir no visualizador do Python a função merge_lsts() trabalhando.
Você também pode assistir o visualizador trabalhando diretamente na página do cscircles.
Vamos agora determinar o consumo de tempo da função merge_lsts().
A tabela a seguir mostra o consumo de tempo assintótico de cada linha da função.
Temos que tomar um certo cuidado aqui.
Ao contar o número de execuções de cada linha estamos supondo que o consumo de tempo da linha é constante, ou seja \(\mathtt{\textup{O}(1)}\).
O consumo de tempo das linhas 9 e 10 podem não ser constantes.
Quando a função chega na linha 9 sabemos que i = m ou j = n, ou seja, ou a lista v1[i:] é vazia ou a lista v2[j:] é vazia.
Assim, se supormos que i = m então o consumo de tempo da linha 0 será \(\mathtt{\textup{O}(1)}\) e o consumo de tempo da linha 10 será
proporcional a n-j. Se j = n temos uma situação semelhante.
No caso, independentemente se i = m ou j = n isso não fará diferença para o cômputo geral.
O ponto será que, para cada elemento de v1 e cada elemento de v2, a função merge_lsts() consumirá uma quantidade de tempo constante.
Conclusão. O consumo de tempo da função
merge_lsts(v1, v2)é proporcional a \(\mathtt{m+n = \textup{O}(m+n)}\) em que \(\mathtt{m}\) é o número de elementos dev1e \(\mathtt{n}\) é o número de elementos dev2.
Intercalação de sublistas#
Agora resolveremos a versão do problema de intercalação que usaremos no nosso algoritmo de ordenação que utiliza a estratégia de dividir para conquistar
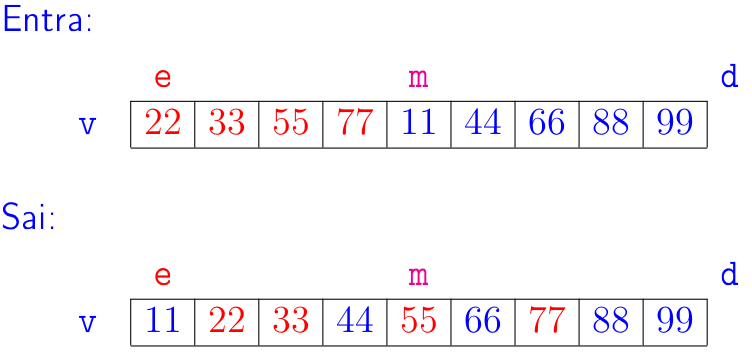
Problema de intercalação de sublistas: Dados uma lista
ve índicese,medtais quev[e:m]ev[m:d]são crescentes, rearranjar os elementos dev[e:d]de modo que fique crescente.
A seguir está uma ilustração para o problema de intercalação de sublistas.
No exemplo, e podem ser o índice de uma posição qualquer, não precisa ser 0.
Para quais valores de índices e, m e d o problema faz sentido?
Como exercício escreva uma função merge() com a seguinte especificação.
def merge(v, e, m, d):
''' (list, int, int, int) -> None
RECEBE uma lista v e índices e, m e d tais que v[e:m] e v[m:d] são crescentes.
REARRANJA os elementos de v[e:d] para que fiquem em ordem crescente.
'''
O consumo de tempo de sua função deve ser \(\mathtt{\textup{O}(n)}\) em que \(\mathtt{n = d-e}\) é o número de elementos na lista v[e:d].
Em busca de inspiração?
A função merge() será muito semelhante a função merge_lsts().
Aqui está uma possível sequência de passos:
crie uma lista auxiliar de tamanho \(\mathtt{n = d-e}\);
intercale as sublistas
v[e:m]ev[m:d]dev[e:d]e armazene o resultado desta intercalação na lista auxiliar.copie o conteúdo da lista auxiliar para
v[e:d].
Abaixo estão alguns exemplos que mostram no IPython Shell o comportamento da função merge()
In [2]: v = [7, 11, 56, 5, 7, 99, 104]
In [3]: merge(v, 0, 3, 7) # retorna None
In [4]: seq
Out[4]: [5, 7, 7, 11, 56, 99, 104]
In [5]: v = [7, 11, 56, 5, 7, 99, -1]
In [6]: merge(v, 1, 3, 6) # v[1:3] = [11, 56] e v [3:6] = [5, 7, 99]
In [7]: v # v[1:6] crescente
Out[7]: [7, 5, 7, 11, 56, 99, -1]
In [8]: v = [0, 1, 2, 3, 7, 11, 56, 5, 7, 99, 104]
In [9]: merge(v, 4, 7, 11) # v[4:7] = [7, 11, 56] v[7:11] = [5, 7, 99, 104]
In [10]: v # v[4:11] crescente
Out[10]: [0, 1, 2, 3, 5, 7, 7, 11, 56, 99, 104]
In [11]: v = [99, 99, 99, 99, 7, 11, 56, 5, 7, 59, -1]
In [12]: merge(v, 4, 7, 11) # v[4:7] = [7, 11, 56] v[7:10] = [5, 7, 99]
In [13]: v # v[4:10] crescente
Out[13]: [99, 99, 99, 99, 5, 7, 7, 11, 56, 59, -1]
Mergesort#
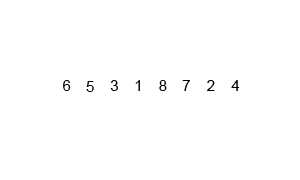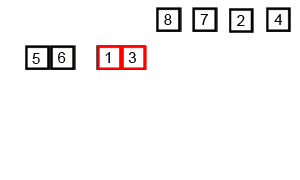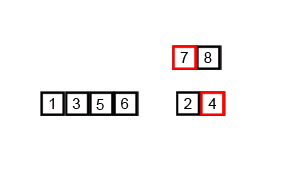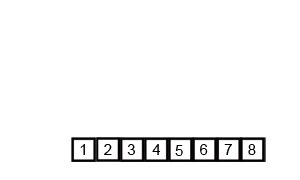
Agora partiremos para o método de ordenação por intercalação que utiliza a estratégia de dividir para consquistae e que se apoia com todas suas forças no
pensamento recursivo e na colaboração indispensável da função merge(v, e, m, d).
A estratégia da ordenação por intercalação está ilustrada no diagrama a seguir. Esse diagrama indica que em cada nível da recursão temos três passos:
ordenaremos recursivamente a sublista formada pela metade esquerda da lista;
ordenaremos recursivamente a sublista formada pela metade direita da lista; e
intercalaremos as sublistas esquerda e direita.
A função que é a porta de entrada para a estratégia chama-se mergesort() e está logo abaixo.
def mergesort(v):
'''(list) -> None
RECEBE uma lista v.
REARRANJA os elementos de v para que fiquem em ordem crescente.
'''
n = len(v)
mergesortR(v, 0, n)
Contemplemos alguns exemplos de execução da função mergesort() no IPython Shell:
In [2]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1]
In [3]: mergesort(v)
In [4]: v
Out[4]: [-1, -1, 5, 7, 7, 11, 17, 56, 58, 59, 99]
In [11]: v = ['como', 'é', 'muito', 'bom', 'estudar', 'mac0122!']
In [12]: mergesort(v)
In [13]: v
Out[13]: ['bom', 'como', 'estudar', 'mac0122!', 'muito', 'é']
A função mergesort() é uma envoltória para a função recursiva mergesortR() que faz todo o serviço.
Hmm. 🤔 Na verdade, na verdade, todo o trabalho duro fica mesmo para a máquina intercaladora merge().
A especificação da função mergesortR() é a seguinte.
def mergesortR(v, e, d):
'''(list, int, int) -> None
RECEBE uma lista v e índice e e d.
REARRANJA os elementos de seq[e:d] para que fiquem em ordem crescente.
'''
Aqui estão alguns exemplos de execução da função mergesortR() no IPython Shell.
In [46]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1]
In [47]: mergesortR(v, 0, 5)
In [48]: v
Out[48]: [-1, 7, 17, 58, 99, 11, 56, 5, 7, 59, -1]
In [49]: mergesortR(v, 5, 11)
In [50]: v
Out[50]: [-1, 7, 17, 58, 99, -1, 5, 7, 11, 56, 59]
In [51]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1]
In [52]: mergesortR(v, 0, 6)
In [53]: v
Out[53]: [-1, 7, 11, 17, 58, 99, 56, 5, 7, 59, -1]
In [54]: mergesortR(v, 6, 11)
In [55]: v
Out[55]: [-1, 7, 11, 17, 58, 99, -1, 5, 7, 56, 59]
Agora vejamos a ilustração de alguns trechos da simulação de mergesortR(v,e,d):
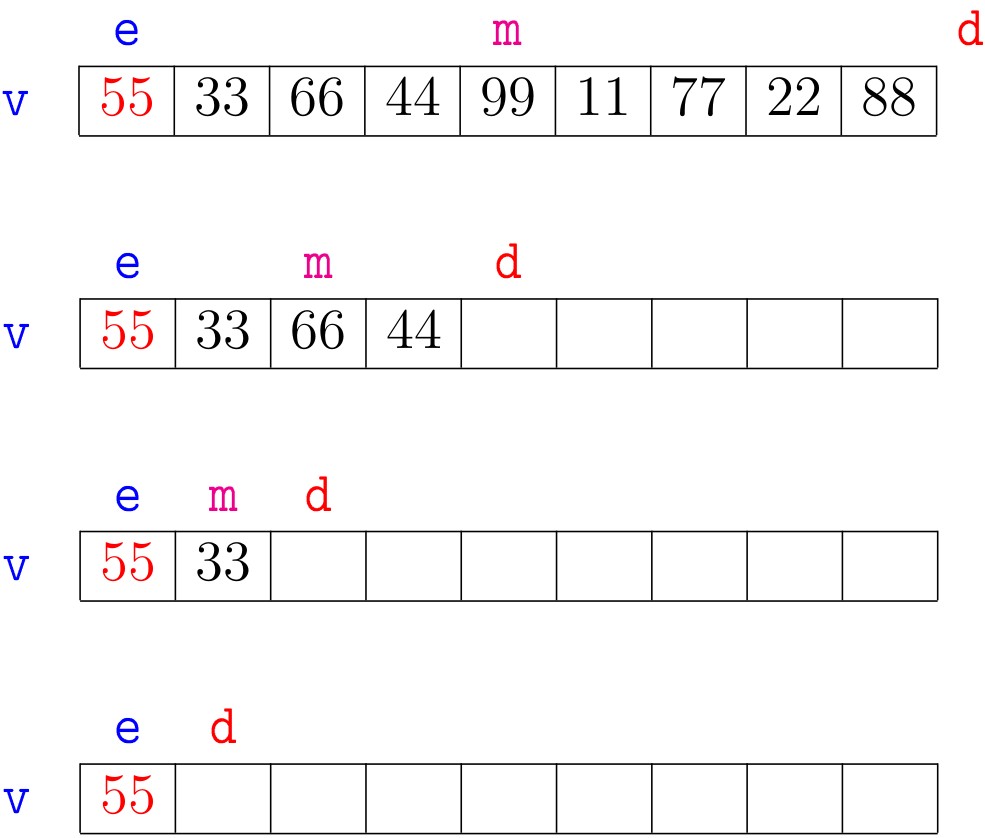
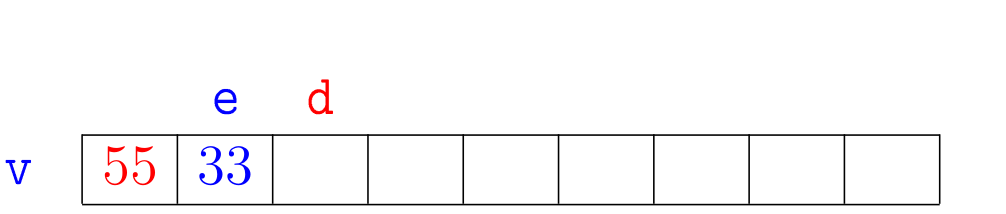
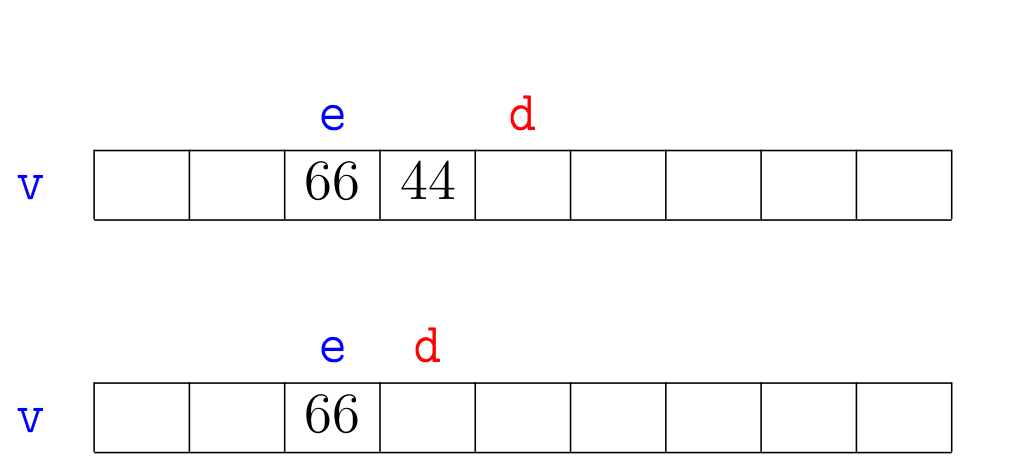
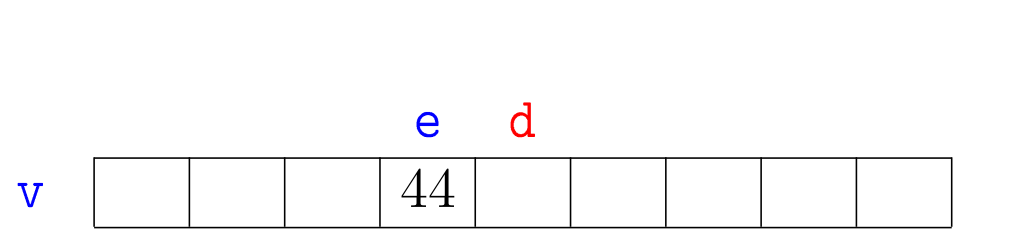
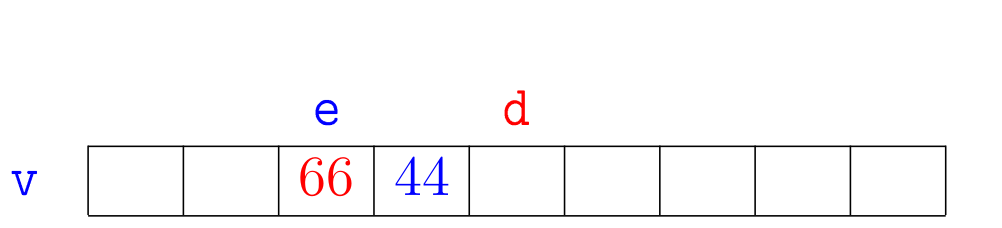
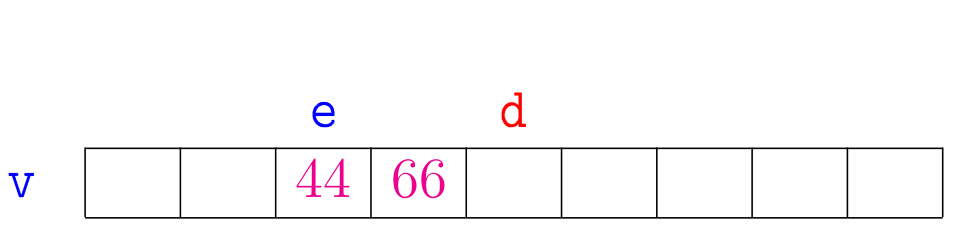
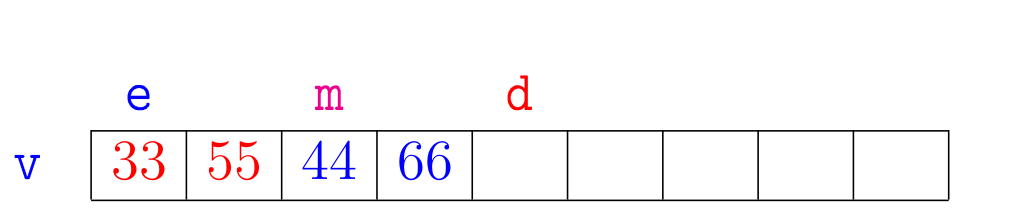

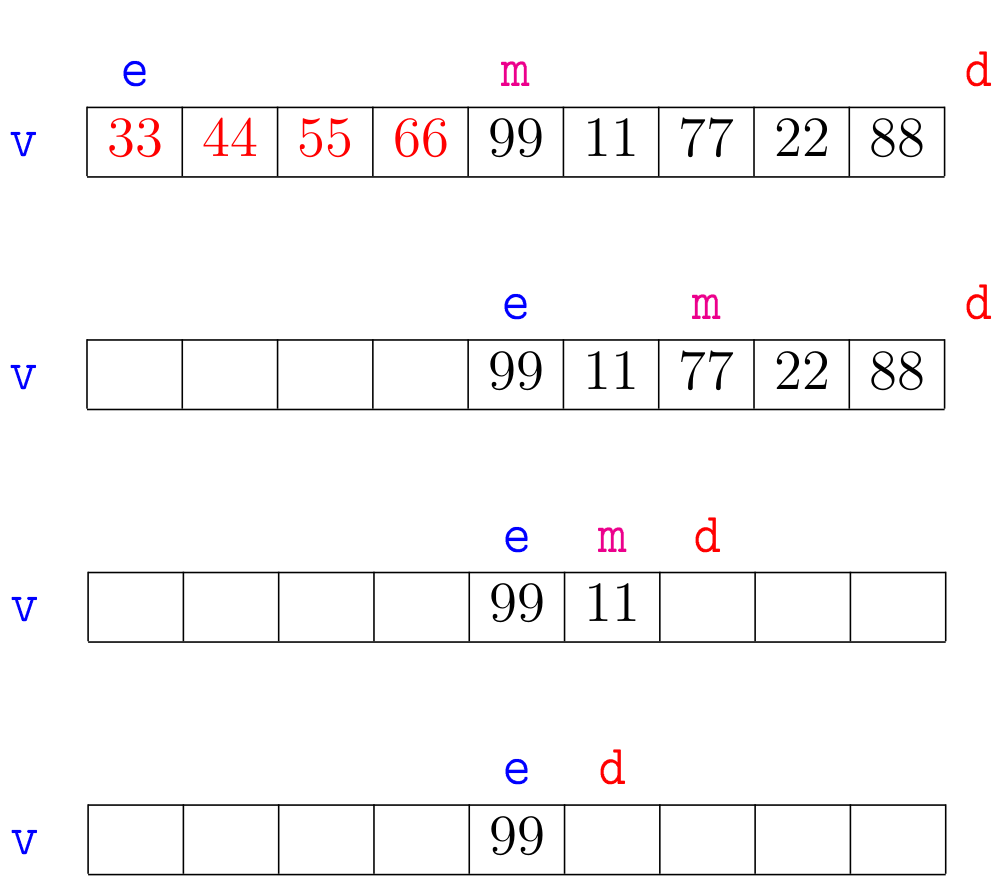
A correção da função mergesortR(), que se apoia na correção da função
merge(), pode ser demonstrada por indução matemática no número \(\mathtt{n = d-e}\) de elementos na sublista dada.
O consumo de tempo da função mergesortR() também se sustenta no consumo de tempo da função merge().
Esse consumo de tempo pode ser intuído observando a estrutura das chamadas recursivas.
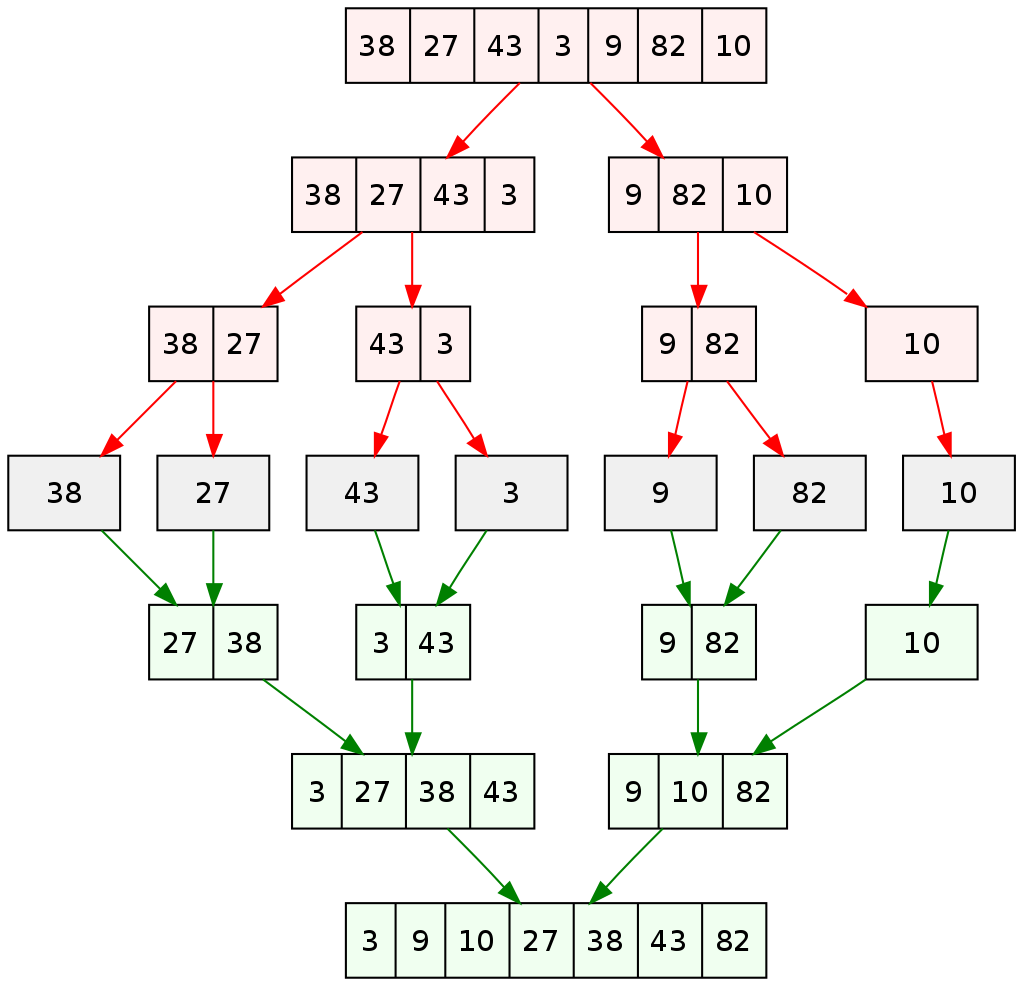
A árvore da recursão da execução de mergesortR(v,0,n) é a seguinte.
O consumo de tempo em cada nível da recursão é proporcional a n.
Há cerca de \(\mathtt{\lg n}\) níveis.
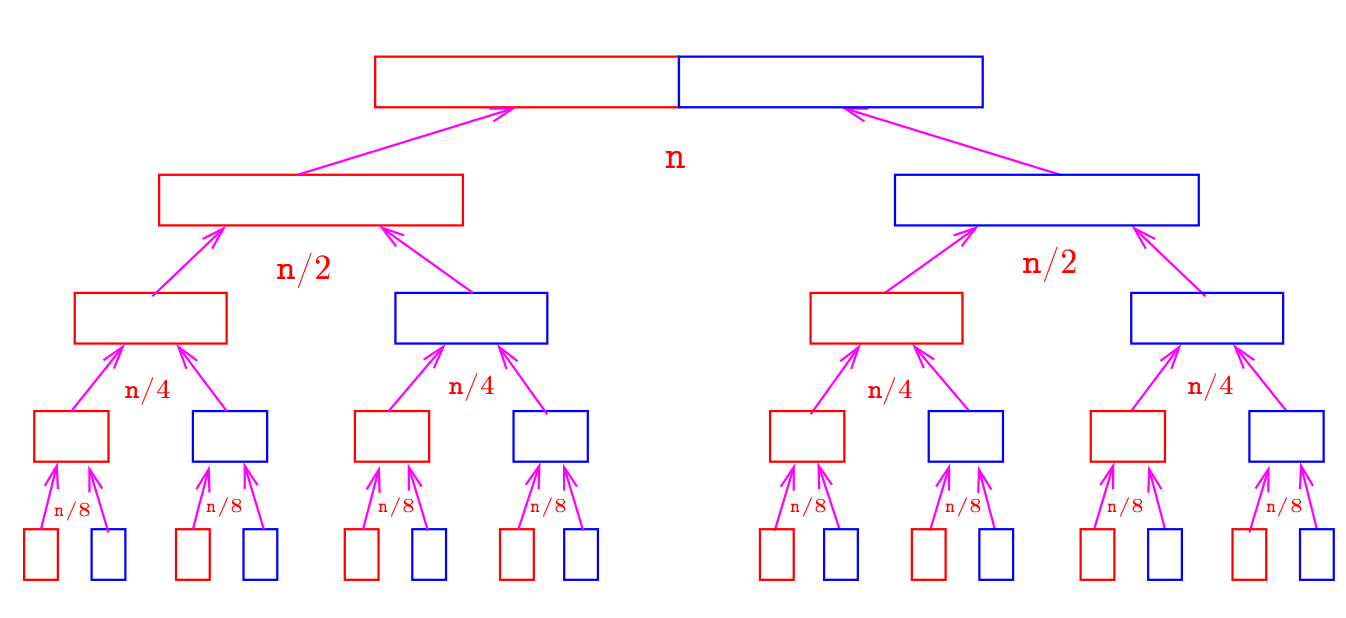
Do ponto de vista prático esse consumo de tempo indica que se o tempo gasto por mergesortR(v,0,n) para ordenar uma lista
com n elementos é \(\mathtt{t}\) segundos/minutos/horas/…, então o tempo gasto por mergesortR(v,0,2n) deve ser pouco mais que \(\mathtt{2t}\) segundos/minutos/horas/…
Isso se deve ao fato de que \(\mathtt{\lg n}\) é uma função que cresce muito mais lentamente que \(\mathtt{n}\).
Esse impressão vaga será colocada à prova através de experimentos.
Conclusão. O consumo de tempo da função
mergesortR()é proporcional a \(\mathtt{n \lg n= \textup{O}(n \lg n)}\) em que \(\mathtt{n}\) é o número de elementos na lista fornecida à função.
Este é um bom momento para fixarmos a nossa ideias através de exercícios.
Desenvolva uma implementação das funções merge() e mergesortR().
As animações mais adiante ilustram o funcionamento do trabalho combinado das funções mergesort(), mergesortR() e merge() e podem também servir de inspiração.
Se for conveniente você pode escrever e testar suas funções na janela a seguir.
Para ilustrar mais ainda a ordenação por intercalação feita pela função mergesort() seguem algumas animações.
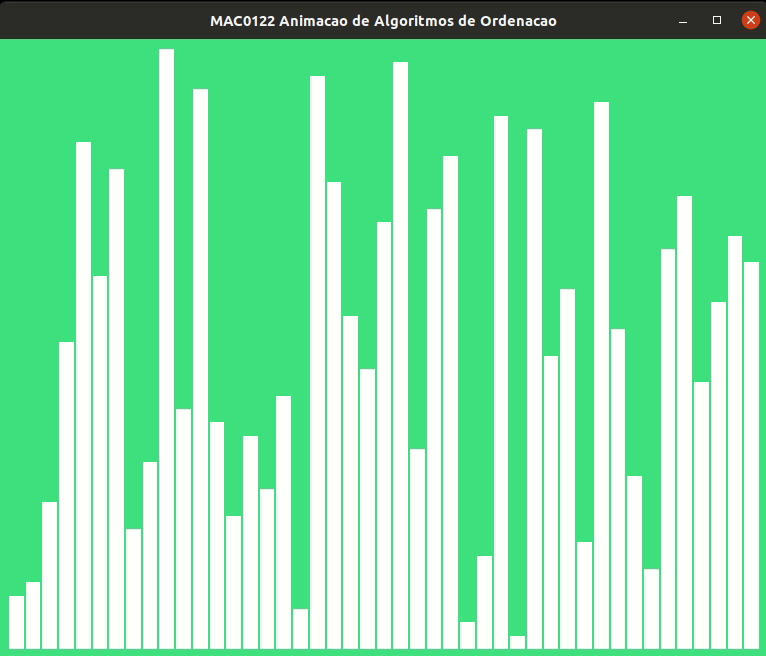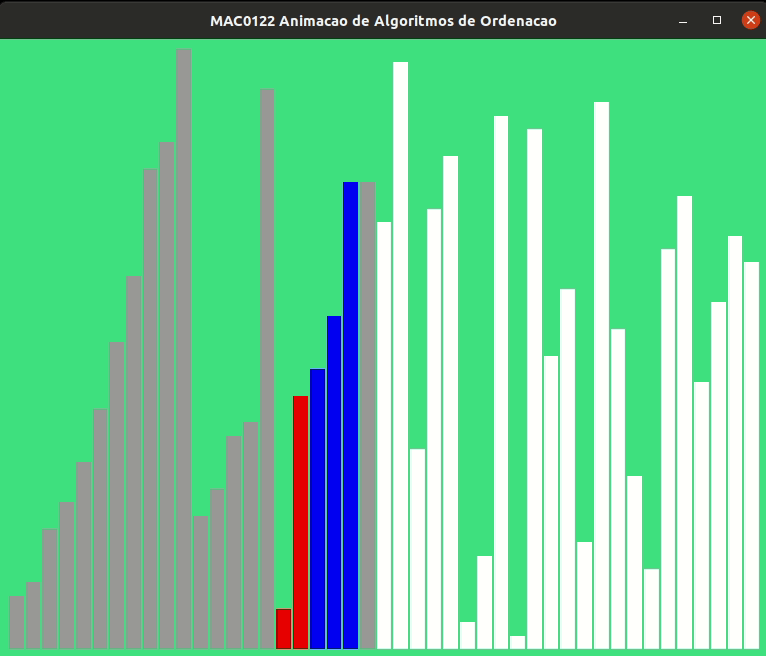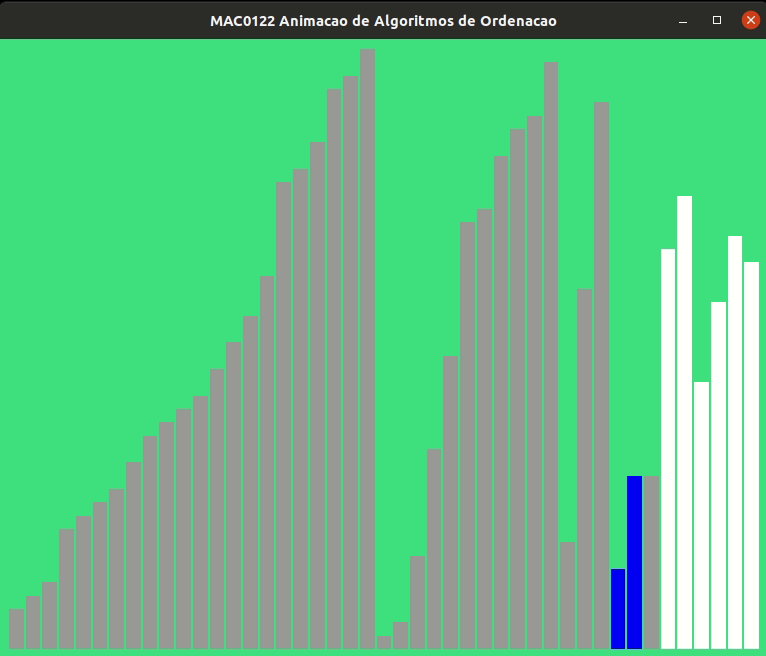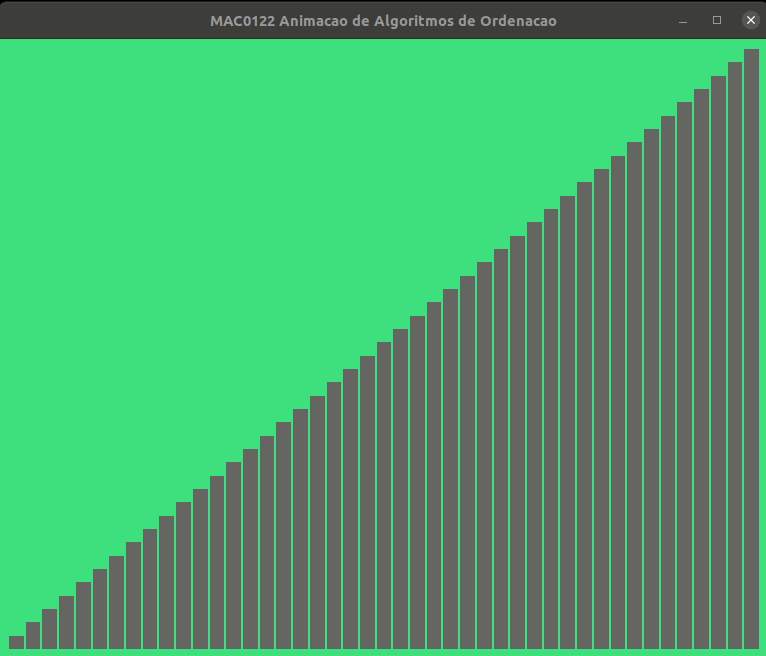
Mergesort iterativo#
A seguinte função mergesortI() implemente uma versão iterativa da função mergesort().
Assim como mergesortR(), a função mergesortI() também se sustenta na máquina de itercalação que é a função merge(v,e,m,d).
def mergesortI(v):
'''(list) -> None
RECEBE uma lista v.
REARRANJA os elementos de v para que fiquem em ordem crescente.
'''
0 n = len(v)
1 b = 1 # tamanho dos pares de blocos a serem intercalados
2 while b < n:
3 e = 0
4 while e + b < n:
5 d = e + 2*b
6 if d > n: d = n
7 merge(v, e, e+b, d)
8 e = d
9 b = 2*b # dobre o tamanho dos blocos
Seguem alguns exemplos de execução da função mergesortI().
In [34]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1]
In [35]: mergesortI(v)
In [36]: v
Out[36]: [-1, -1, 5, 7, 7, 11, 17, 56, 58, 59, 99]
In [37]: v = ['como', 'é', 'muito', 'bom', 'estudar', 'mac0122!']
In [38]: mergesortI(v)
In [39]: v
Out[39]: ['bom', 'como', 'estudar', 'mac0122!', 'muito', 'é']
Para entender o seu funcionamente, pode ser útil examinar a seguinte animação.
A função mergesortI() é uma versão iterativa da ordenação por intercalação, também chamada de implementação bottom-up do Mergesort.
O Mergesort iterativo é divido em fases.
No início de cada fase tem-se que a lista está dividida/particionada em sublistas crescentes, cada uma das quais com b elementos.
No início da primeira fase b = 1.
Em cada fase a função percorre a lista do seu início ao fim intercalando pares de sublistas crescentes vizinhas com b elementos.
Ao final de uma fase tem-se que a lista está particionada em sublistas crescentes de \(2\times\) b elementos,
com exceção feita, possivelmente, à sublista do final da lista.
Desta forma a próxima fase pode ser iniciada com \(2\times\) b no papel do novo tamanho b das sublistas ordenadas.
No início da 1a. fase a lista está dividida em sublistas ordenadas com
b=1elemento.No início da 2a. fase a lista está dividida em sublistas ordenadas com
b=2elementos.No início da 3a. fase a lista está dividida em sublistas ordenadas com
b=4elementos.No início da 4a. fase a lista está dividida em sublistas ordenadas com
b=8elementos.
Em geral, na fase \(\mathtt{i}\), cada sublista tem \(\mathtt{2^{i-1}}\) elementos. A função para no início da fase \(\mathtt{t}\) em que \(\mathtt{b=2^{t-1}}\) é maior ou igual ao número de elementos da lista.
O consumo de tempo de cada fase é \(\mathtt{\textup{O}(n)}\).
Se o número de fases é \(\mathtt{k}\) concluímos que o consumo de tempo da
função mergesortI() é \(\mathtt{\textup{O}(k \times n)}\).
Hmm. Qual o número de fases necessárias para se ordenar uma lista com n elementos em termos de n? 🙂
Aqui vai uma pequena simulação…
+----+----+----+----+----+----+----+----+----+
| 55 | 33 | 66 | 44 | 99 | 11 | 77 | 22 | 88 | b = 1
+----+----+----+----+----+----+----+----+----+
e m d
e m d
e m d
e m d
e m d # faz nada
+----+----+----+----+----+----+----+----+----+
| 33 | 55 | 44 | 66 | 11 | 99 | 22 | 77 | 88 | b = 2
+----+----+----+----+----+----+----+----+----+
e m d
e m d
e faz nada
+----+----+----+----+----+----+----+----+----+
| 33 | 44 | 55 | 66 | 11 | 22 | 77 | 99 | 88 | b = 4
+----+----+----+----+----+----+----+----+----+
e m d
+----+----+----+----+----+----+----+----+----+
| 11 | 22 | 33 | 44 | 55 | 66 | 77 | 99 | 88 | b = 8
+----+----+----+----+----+----+----+----+----+
e m d
e faz nada
+----+----+----+----+----+----+----+----+----+
| 11 | 22 | 33 | 44 | 55 | 66 | 77 | 88 | 99 | b = 16
+----+----+----+----+----+----+----+----+----+
e m d
Experimentos com mergesort#
Aqui estão os resultados de alguns experimentos obtidos ordenando-se listas aleatórias com o algoritmo de:
ordenação por inserção:
insercao();ordenação por inserção binária (presente na classe
DicioB):insercaoB();ordenação por intercalação, versão recursiva:
mergeR(); eordenação por intercalação, versão iterativa:
mergeI().
Os tempos estão em segundos.
n insercao insercaoB mergeR mergeI
256 0.00 0.00 0.00 0.00
512 0.01 0.01 0.00 0.00
1024 0.04 0.02 0.00 0.00
2048 0.15 0.08 0.00 0.00
4096 0.59 0.31 0.01 0.01
8192 2.34 1.21 0.02 0.02
16384 10.13 5.19 0.05 0.05
32768 47.89 26.88 0.10 0.10
Como fica claro olhando os resultados experimentais, em termos de tempo gasto, as funções da família dos algoritmos de ordenação por inserção não são páreo para as funções da família do Mergesort. Aqui podemos observar que ao dobrarmos o número de elementos da lista a ser ordenada o tempo gasto pela ordenação por inserção, não importa a versão, aproximadamente quadruplica e o tempo gasto pelo Mergesort, também não importa a versão, pouco mais que dobra.
A bem da verdade, a ordenação por inserção tem algumas vantagens em relação ao Mergesort. O espaço extra usado por uma função são as suas variáveis auxiliares ou colaboradoras que permitem que ajudam a função a fazer o seu serviço. A ordenação por inserção utiliza como espaço extra umas poucas variáveis, umas duas ou três. Como o número dessas variáveis não depende do número de elementos da lista dizemos que o espaço extra utilizado pela ordenação por inserção é constante, em símbolo \(\mathtt{\textup{O}(1)}\). Já o Mergesort, pelo menos nossa versão, utiliza como espaço extra uma lista com o mesmo número de elementos da lista dada. Isso significa que o espaço extra utilizado pelo Mergesort é aproximadamente igual ao número de elementos da lista recebida. Logo o espaço extra utilizado pelo Mergesort é \(\mathtt{\textup{O}(n)}\).
A ordenação por inserção tem outras vantagens em relação ao Mergesort. Para listas com poucos elementos o tempo gasto pela ordenação gasta menos tempo que o Mergesort. Para comprovar essa afirmação devemos preparar experimentos que inclusivem determinam de uma forma clara um certo número inteiro k que será a nossa medida de poucos elementos: menos que k elementos será o que chameremos de pouco. Esse fato sugere o desenvolvimento de algoritmos e funções híbridas que sejam um combinado de métodos trabalhando colaborativamente. Essas funções híbridas são uma outra história que ficarão para uma próxima oportunidade.
Separação de listas#
Encararemos agora um subproblema que será o motor da fase de dividir de uma outra estratégia de dividir para conquistar para ordenação. Como já fizemos com o Mergesort, esse ainda não é exatamente o subproblema que utilizaremos para dividir, mas se aproxima muito. 🙂
No que segue será conveniente utilizarmos algumas abreviaturas. Escreveremos \(\mathtt{v[i: j] \leq x}\) como uma abreviatura de \(\mathtt{val \leq x}\) para todo \(\mathtt{val}\) em \(\mathtt{v[i: j]}\). De maneira semelhante escreveremos \(\mathtt{v[i: j] \leq v[k: m]}\) como uma abreviatura de \(\mathtt{val1 \leq val2}\) para todo \(\mathtt{val1}\) em \(\mathtt{v[i: j]}\) e \(\mathtt{val2}\) em \(\mathtt{v[k: m]}\). O mesmo se aplica para outros operadores relacionais como \(\mathtt{\geq, <, >}\).
Problema da separação de listas: Dada uma lista
v, rearranjar seus elementos e determinar um índice \(\mathtt{i}\) de tal forma que tenhamos que \(\mathtt{v[0:i] \leq v[i] < v[i+1:n]}\) em que \(\mathtt{n}\) é o número de elementos dev.
Por exemplo:
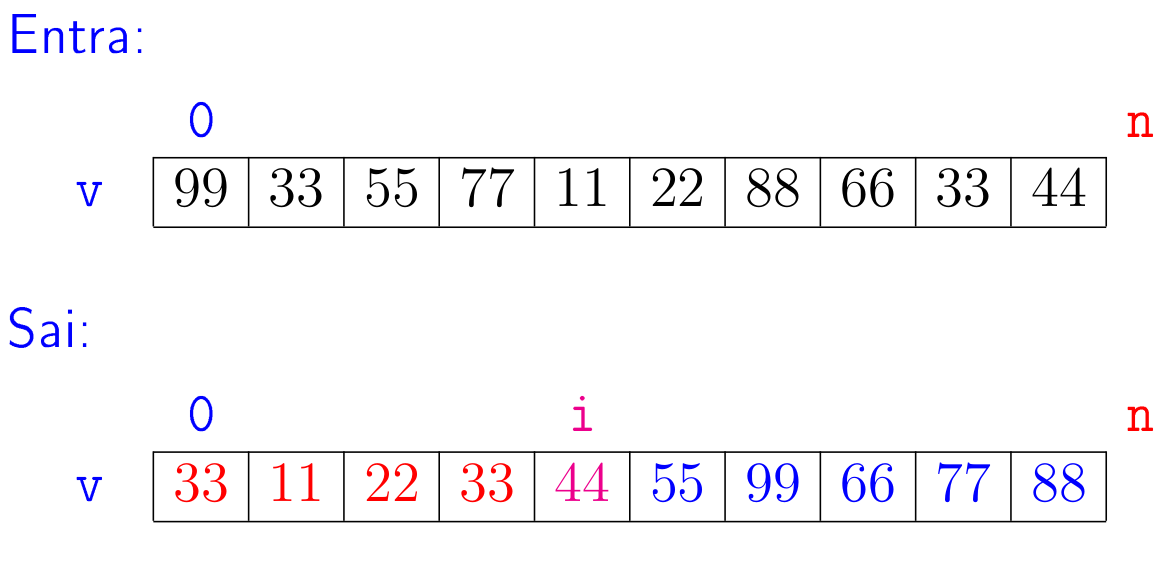
É evidente que para resolver o problema da separação de listas podemos simplesmente fazer
1 mergesort(v)
# escolha um índice quaquer
2 n = len(v)
3 i = n//2 # ou i = random.randrange(n)
O problema com essa solução é o seu consumo de tempo.
A linha 1 consome tempo \(\mathtt{\textup{O}(n \lg n)}\) em que \(\mathtt{n}\) é o número de elementos em v.
Note que o problema pede por muito menos que uma lista crescente.
O problema pede apenas que um elemento que chamaremos de pivô divida-a em duas sublistas, a dos elementos menores ou iguais que o pivô e a dos elementos maiores que o pivô.
É claro que ordenar a lista resolve o problema.
No entanto, como esta sendo pedido menos poderemos fazer esse serviço, resolver o problema de forma muito mais efeciente.
A maneira que resolveremos será tão eficiente que acabará sendo utilizada como subrotina para ordenarmos a lista de maneira muito rápida.
Essa será uma espécie de ordenação baseada em separação, uma ordenação por separação.
Há muitas ideias muito bacanas e eficientes para resolvermos o problema da separação de listas. 👍🏾
Veremos a simulação de uma dessas ideias e depois a função separe_lst() que implementa essas ideia.
O algoritmo sobre o qual trabalharemos é iterativo.
Inicialmente selecionamos um elemento x de v para ser o pivô da separação.
O nome pivô para x é devido ao fato que ele terá um papel de destaque no algoritmo.
Ao final x será o elemento sentando em v[i], a posição de separa os elementos de v que são menores ou iguais a x daqueles que são maiores que x.
O algoritmo manterá a seguinte relação invariante no início de cada iteração:
v[0:i+1] <= x < v[i+1:j]
Vejamos uma simulação do algoritmo.
Escolheremos o pivô x como sendo o último elemento da lista, ou seja, em Python, x = v[-1].
Observe na simulação o papel de j como uma espécie de batedor que vai à frente percorrendo a lista e i tem o papel de manter os elementos menores ou iguais a x a sua esquerda.

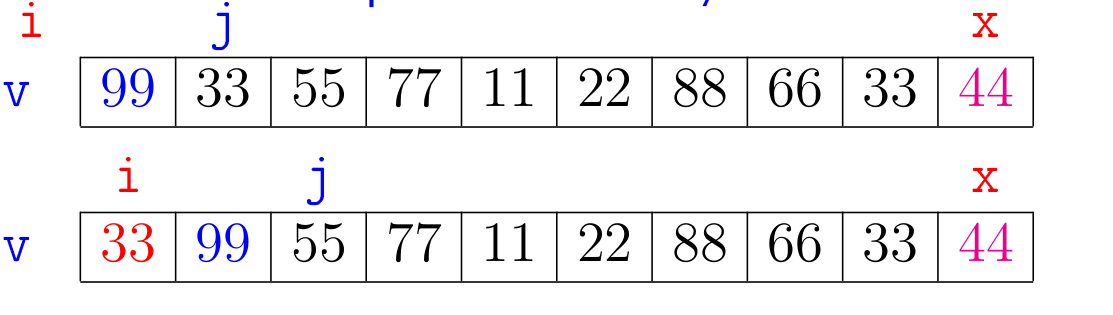

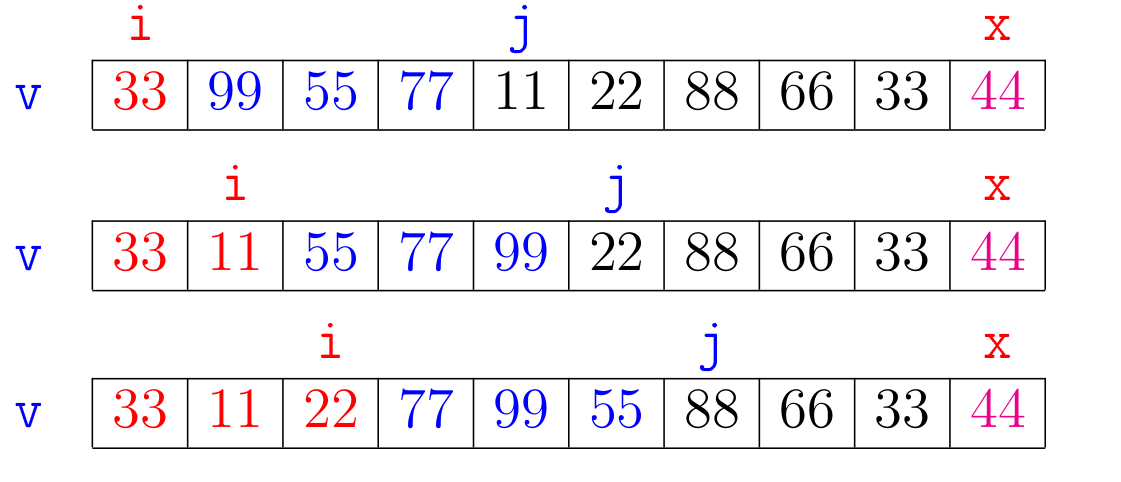




Ao final do algoritmo temos que \(\mathtt{x}\) é o elemento na posição \(\mathtt{v[i]}\) e que \(\mathtt{j = n}\).
Consequentemente a relação invariante, trocando \(\mathtt{j}\) por \(\mathtt{n}\), nos diz que
\(\mathtt{v[0:i] \leq x = v[i] < v[i+1:n]}\).
Portanto, a relação invariante garante que ao final teremos que a nossa função separe_lst() resolve o problema.
A função separe_lst() abaixo segue fielmente os passos da simulação.
Como de hábito, os números no início de algumas linhas não fazem parte do código e só existem para mais adiante fazermos referências às linhas.
def separe_lst(v):
'''(list) -> int
RECEBE uma lista v com pelo menos 1 elemento.
Chamaremos de pivô o elemento na posição v[-1].
REARRANJA os elementos de v e RETORNA um índice i de tal forma
que v[0: i] <= v[i] < v[i+1:n].
'''
1 n = len(v)
2 x = v[-1] # pivô
3 i = -1
4 for j in range(n): #A#
5 if v[j] <= x:
6 i += 1
7 v[i], v[j] = v[j], v[i]
8 return i
A relação invariante vale no ponto #A# do código.
Antes de continuarmos, tendo em vista que no final das contas estamos interessados em rearranjar os elementos de uma lista de tal forma que ela fique crescente,
vale a pena notar que após a execução de separe(v) teremos que:
o elemento
xsentado na posiçãov[i], o pivô, está na sua posição de direito na lista crescente! 🥇
Talvez valha a pena assistir a animação a seguir para nos familiarizarmos mais ainda com o funcionamento da função separe_lst().
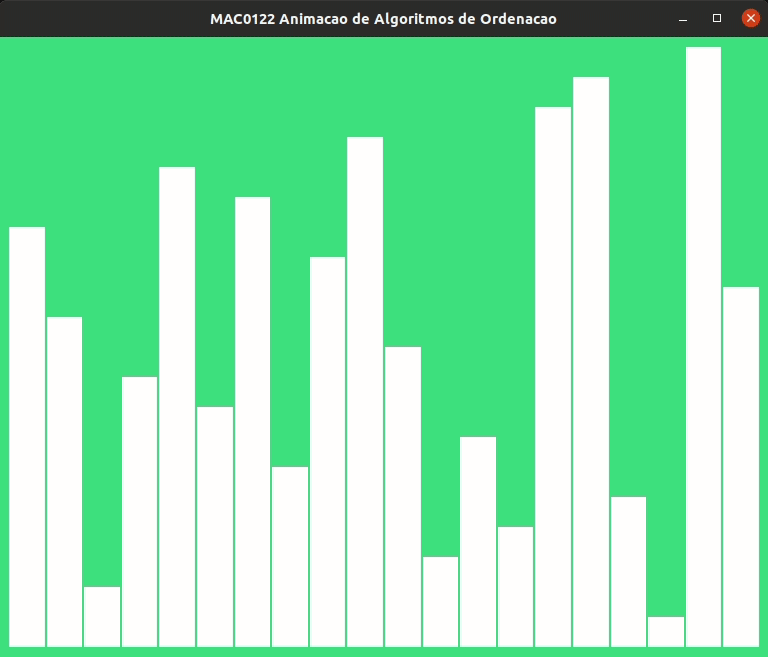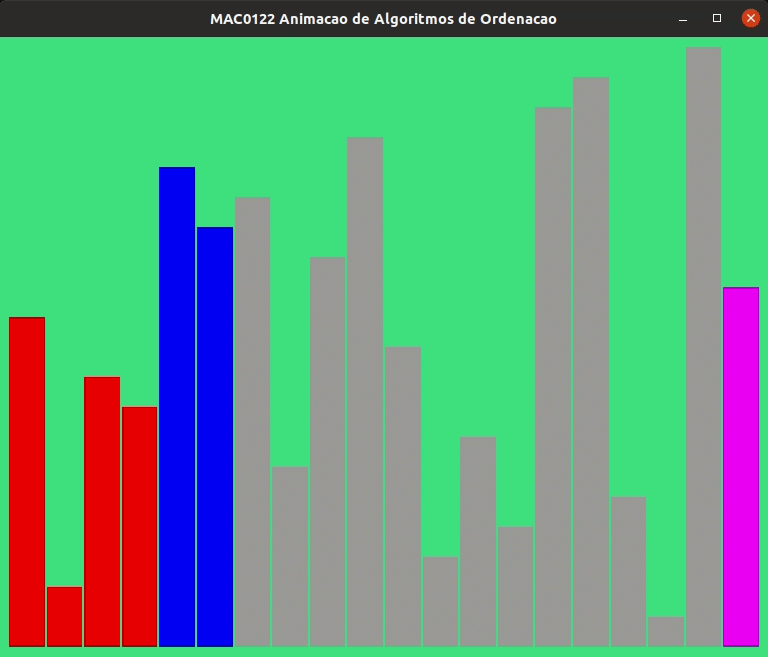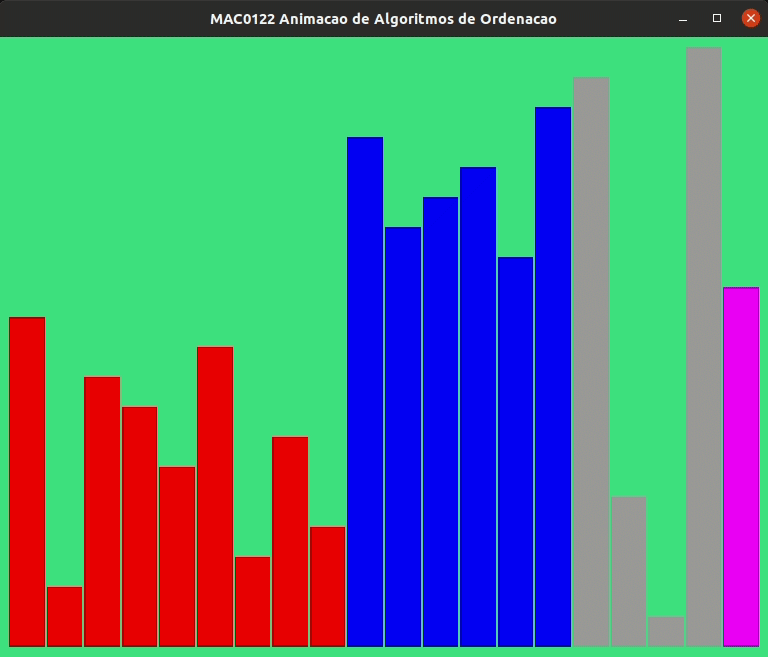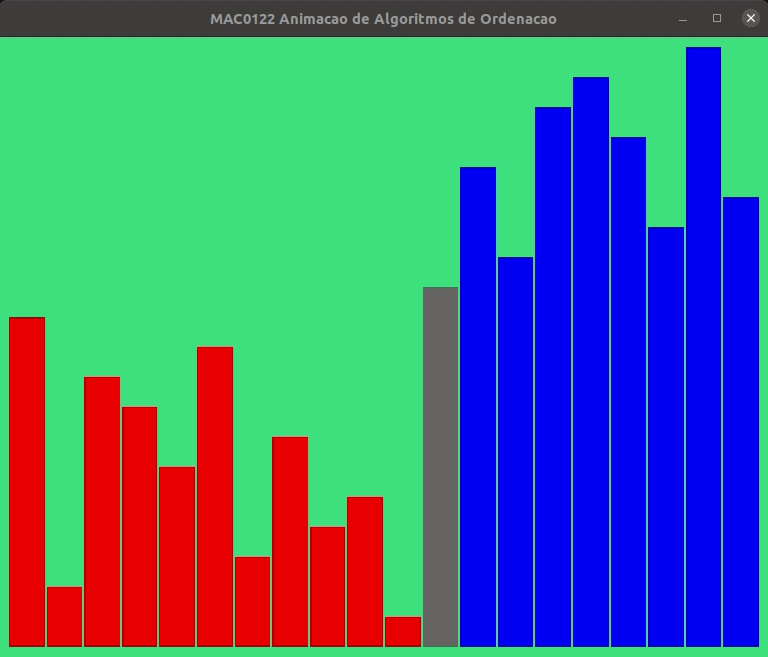
Vamos supor que o consumo de tempo de cada linha é 1 unidade de tempo ou, equivalentemente, é \(\mathtt{\textup{O}(1)}\).
Essa hipótese significa que o tempo gasto na execução de cada linha da função não depende do número de elementos na lista.
Essa é uma hipótese razoável e honesta! De fato, em vista que em nenhuma linha da função vemos algo como x in v, sum(v), ou um fatiamento como v[k:m], ou outro comando nativo de Python que envolva percorrer uma porção razoável da lista, como por exemplo metade da lista, ou um quarto da lista ou \(\ldots\) um centésimo de lista ou \(\ldots\)
Separação de sublistas#
Vejamos agora para versão do problema da separação que usaremos no nosso novo algoritmo de ordenação que utiliza a estratégia de dividir para conquistar
Problema de separação de sublistas: Dada uma lista
ve índiceseed, \(\mathtt{e < d}\), rearranjar os elementos dev[e:d]e determinar um índice \(\mathtt{m}\), \(\mathtt{e \leq m < d}\), de tal forma que tenhamos que \(\mathtt{v[e:m] \leq v[m] < v[m+1:d]}\).
A seguir está uma ilustração para o problema de intercalação de sublistas.
No exemplo, e e d podem ser o índices quaisquer, não precisa ser 0 e n.
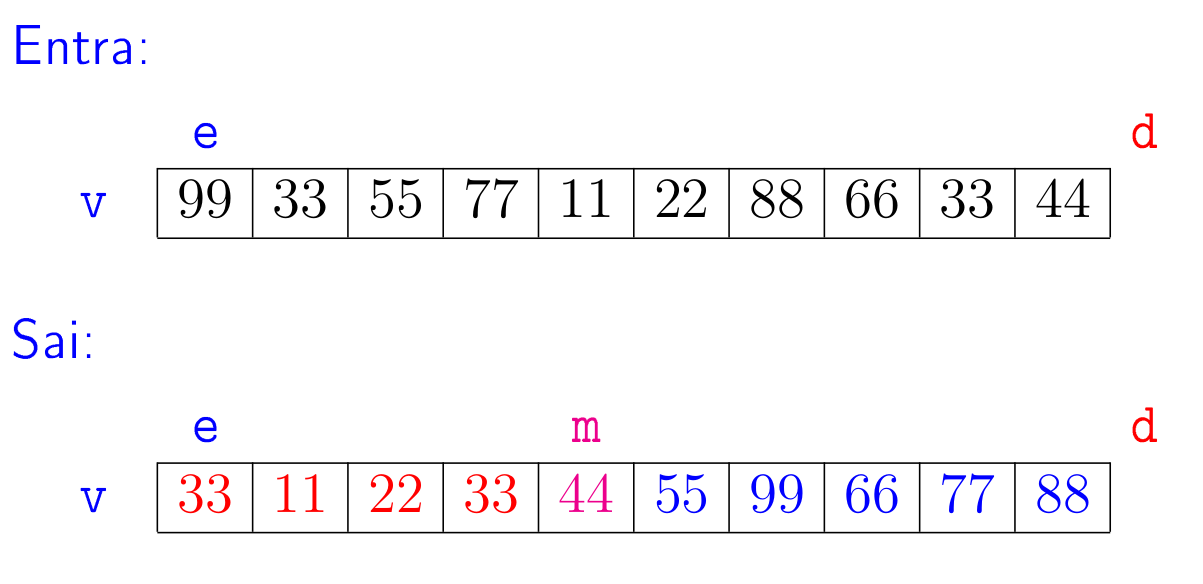
Como exercício escreva uma função separe() com a seguinte especificação.
def separe(v, e, d):
''' (list, int, int) -> int
RECEBE uma lista v e dois inteiros 0 <= e < d <= len(v).
REARRANJA os elementos de v[e:d] e RETORNA um índice m,
e <= m < d de tal forma que v[e: m] <= v[m] < v[m+1: d].
'''
O consumo de tempo da função separe() deve ser \(\mathtt{\textup{O}(n)}\).
Utilize o elemento da posição v[d-1]
Em busca de inspiração?
A função separe() é muito semelhante a função separe_lst().
Aqui vão alguns exemplos de execução da função para seus testes.
In [2]: v = [7, 11, 56, 5, 7, 99, 104] In [3]: m = separe(v, 0, 7) In [4]: m Out[4]: 6 In [5]: v Out[5]: [7, 11, 56, 5, 7, 99, 104] In [6]: v = [7, 11, 56, 5, 7, 99, 10] In [7]: m = separe(v, 0, 7) In [8]: m Out[8]: 3 In [9]: v Out[9]: [7, 7, 5, 10, 11, 99, 56] In [10]: v = [7, 11, 56, 5, 7, 99, -10] In [11]: m = separe(v, 0, 7) In [12]: m Out[12]: 0 In [13]: v Out[13]: [-10, 11, 56, 5, 7, 99, 7] In [14]: v = [99, 99, 99, 7, 11, 56, 5, 7, 13, -10, -10] In [15]: m = separe(v, 3, 9) In [16]: m Out[16]: 7 In [17]: v Out[17]: [99, 99, 99, 7, 11, 7, 5, 13, 56, -10, -10] In [19]: v = [99, 99, 99, 7, 11, 56, 5, 7, 6, -10, -10] In [20]: m = separe(v, 3, 9) In [21]: m Out[21]: 4 In [22]: v Out[22]: [99, 99, 99, 5, 6, 56, 7, 7, 11, -10, -10]
Quicksort#
Chegou o momento da função separe() socorrer o problema da ordenação.
Partiremos para o método de ordenação por separação que se molda em dividir para consquistar e se apoia com todo seu peso na função separe(v,e,d).
Essa estratégia de ordenação é conhecida pelo nome de Quicksort.
O plano do algoritmo está ilustrado na animação a seguir. Em cada nível da recursão temos três passos:
separamos a lista em sublistas de acordo com um elemento pivô;
ordenaremos recursivamente a sublista dos elementos à esquerda do pivô; e
ordenaremos recursivamente a sublista dos elementos à direita do pivô.
De maneira semelhante ao que já fizemos várias vezes, inclusive com a função mergesort(), a
função quicksort() é apenas uma envoltória para a função quicksortR() que faz todo o trabalho.
Na verdade, quem faz todo o trabalho é a função separe().
A função quicksortR() faz o papel de agenciadora do trabalho de separe().
def quicksort(v):
'''(list) -> None
RECEBE uma lista v.
REARRANJA os elementos de v para que fiquem em ordem crescente.
'''
n = len(v)
quicksortR(v, 0, n)
Aqui vão alguns exemplos de execução de quicksort().
In [2]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1]
In [3]: quicksort(v)
In [4]: v
Out[4]: [-1, -1, 5, 7, 7, 11, 17, 56, 58, 59, 99]
In [11]: v = ['como', 'é', 'muito', 'bom', 'estudar', 'mac0122!']
In [12]: quicksort(v)
In [13]: v
Out[13]: ['bom', 'como', 'estudar', 'mac0122!', 'muito', 'é']
Contemplemos alguns exemplos de execução da função quicksortR() no IPython Shell:
def quicksortR(v, e, d):
'''(list, int, int) -> None
RECEBE uma lista v e índice e e d.
REARRANJA os elementos de v[e:d] para que fiquem em ordem crescente.
'''
In [57]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1, 22] In [58]: m = separe(v, 0, 12) # divide In [59]: m Out[59]: 7 In [60]: v Out[60]: [-1, 7, 17, -1, 7, 11, 5, 22, 58, 59, 99, 56] In [60]: v Out[60]: [-1, 7, 17, -1, 7, 11, 5, 22, 58, 59, 99, 56] In [61]: quicksortR(v, 0, 7) In [62]: v Out[62]: [-1, -1, 5, 7, 7, 11, 17, 22, 58, 59, 99, 56] In [62]: v Out[62]: [-1, -1, 5, 7, 7, 11, 17, 22, 58, 59, 99, 56] In [63]: quicksortR(v, 8, 12) In [64]: v Out[64]: [-1, -1, 5, 7, 7, 11, 17, 22, 56, 58, 59, 99] In [64]: v Out[64]: [-1, -1, 5, 7, 7, 11, 17, 22, 56, 58, 59, 99] In [65]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1, 0] In [66]: m = separe(v, 0, 12) # divide In [67]: m Out[67]: 2 In [68]: v Out[68]: [-1, -1, 0, 58, 7, 11, 56, 5, 7, 59, 99, 17] In [68]: v Out[68]: [-1, -1, 0, 58, 7, 11, 56, 5, 7, 59, 99, 17] In [69]: quicksortR(v, 3, 12) In [70]: v Out[70]: [-1, -1, 0, 5, 7, 7, 11, 17, 56, 58, 59, 99] In [70]: v Out[70]: [-1, -1, 0, 5, 7, 7, 11, 17, 56, 58, 59, 99] In [74]: v = [99, 99, 17, -1, 7, 11, 56, 5, 7, 9, -10, -10] In [75]: quicksortR(v, 2, 10) In [76]: v Out[76]: [99, 99, -1, 5, 7, 7, 9, 11, 17, 56, -10, -10]
A correção da função quicksortR() será certificada e dependerá quase que inteiramente da correção da função separe().
O consumo de tempo da função quicksortR() também se sustenta no consumo de tempo da função separe().
Para testar a compreensão do Quicksort, desenvolva uma implementação das funções separe() e quicksortR().
Se for conveniente você pode escrever e testar suas funções na janela a seguir.
Quicksort iterativo#
A função quicksortI() que está logo a seguir é uma versão iterativa do Quicksort.
Esta versão iterativa caminha sobre as pegadas da versão recursiva, ou seja, simula a versão recursiva.
Para isso esta versão iterativa usa uma pilha em que os elementos são pares de índices (e, d) sobre os quais ainda devemos aplica a função separe().
A lista pilha na nossa implementação, portanto, simula de uma forma explícita o serviço feito pela pilha da recursão que é implícita na versão recursiva do Quicksort.
Tanto na nossa versão recursiva quanto nossa versão iterativa o espaço extra usado pelo Quicksort no pior caso é proporcional ao número de elementos desta
pilha, que pode ser \(\mathtt{\textup{O}(n)}\), em que \(\mathtt{n}\) é o número de elementos na lista que desejamos ordenar.
Entretanto, se aplicarmos mais algumas ideias podemos trazer este espaço extra para o patamar \(\mathtt{\textup{O}(\lg n)}\).
Mas isso é uma outra história \(\ldots\)
def quicksortI(v):
'''(list) -> None
RECEBE uma lista v.
REARRANJA os elementos de v para que fiquem em ordem crescente.
'''
n = len(v)
e = 0
d = n
pilha = []
pilha.append((e, d))
while pilha != []:
e, d = pilha.pop()
if e < d-1: # v[e: d]) tem pelo menos dois elementos
m = separe(v, e, d)
# empilhe par de índices da sublista esquerda
pilha.append((e, m))
# empilhe par de índice da sublista direita
pilha.append((m+1, d))
Alguns exemplos de execução
In [34]: v = [99, 58, 17, -1, 7, 11, 56, 5, 7, 59, -1]
In [35]: quicksortI(v)
In [36]: v
Out[36]: [-1, -1, 5, 7, 7, 11, 17, 56, 58, 59, 99]
In [37]: v = ['como', 'é', 'muito', 'bom', 'estudar', 'mac0122!']
In [38]: quicksortI(v)
In [39]: v
Out[39]: ['bom', 'como', 'estudar', 'mac0122!', 'muito', 'é']
Experimentos com quicksort#
Aqui estão os resultados de alguns experimentos obtidos ordenando-se listas aleatórias com o algoritmo de:
ordenação por inserção:
insercao();ordenação por inserção binária (presente na classe
DicioB):insercaoB();ordenação por intercalação, versão recursiva:
mergeR();ordenação por intercalação, versão iterativa:
mergeI(); eordenação por separação, versão recursiva:
quick().
Os tempos estão em segundos.
n insercao insercaoB mergeR mergeI quick
256 0.00 0.00 0.00 0.00 0.00
512 0.01 0.00 0.00 0.00 0.00
1024 0.03 0.02 0.00 0.00 0.00
2048 0.14 0.08 0.00 0.00 0.00
4096 0.57 0.30 0.01 0.01 0.01
8192 2.35 1.34 0.02 0.02 0.02
16384 9.66 5.45 0.04 0.04 0.04
32768 37.90 21.44 0.09 0.09 0.08
65536 158.37 90.79 0.20 0.19 0.17
131072 658.00 385.78 0.40 0.39 0.35
O consumo de tempo Mergesort é \(\mathtt{\textup{O}(n \lg n)}\), não importanto se a versão é a recursica mergesortR() ou a interativa mergesortI().
Já o consumo de tempo do Quicksort é \(\mathtt{\textup{O}(n \lg n)}\) no melhor caso e \(\mathtt{\textup{O}(n^2)}\) no pior caso.
Apesar disso, os experimentos mostram que para listas aleatórias o tempo gasto por quicksort() é menor que o gasto por mergesort().
Como um algoritmo que tem consumo de tempo de pior caso \(\mathtt{\textup{O}(n^2)}\) pode gastar menos tempo do que uma outra que
o consumo de tempo é \(\mathtt{\textup{O}(n \lg n)}\)?
Hmm. 🤔 Isso sugere que as listas para as quais o Quicksort faz cerca de \(\mathtt{n^2}\) operações devem ser raras.
A verdade é que podemos demonstrar que, sob algumas hipóteses técnicas porem razoáveis, o consumo de tempo médio
do Quicksort é \(\mathtt{\textup{O}(n \lg n)}\), idêntico ao do Mergesort.
Em termos de espaço extra, o Mergesort utiliza \(\mathtt{\textup{O}(n)}\) variáveis auxiliares enquanto o Quicksort pode ser projetado de tal forma que utilize \(\mathtt{\textup{O}(\lg n)}\) variáveis auxiliares para manter os limites do intervalos que ainda precisam ser ordenados.
Lições#
Note que no Mergesort, após uma sublista ser produzida através da
intercalação de duas outras, não haverá mais comparações entre pares
de elementos nesta sublista. Todo o trabalho será feito comparando-se
elementos entre sublistas separadas. A função merge() é
especializada neste tipo de serviço.
A maior lição aqui é uma ideia genial chamada de divisão e conquista ou dividir para conquistar ou conquista por divisão ou Divide-and-conquer algorithm ou sei lá o que. Esse mesmo arcabouço é usado por ai por uma grande variedade de funções e algoritmos que resolvem os mais diversos problemas!
Algoritmos que aplicam a estratégia de dividir para conquistar são recursivos e têm três passos em cada nível da recursão:
dividir: o problema é dividido em subproblemas parecidos de tamanho menor, até que se tornem simples o suficiente para serem resolvidos diretamente na base da recursão;
conquistar: os subproblemas são resolvidos recursivamente e subproblemas simples/pequenos são resolvidos diretamente; e
combinar: as soluções dos subproblemas são combinadas para obter uma solução do problema original.
No Quicksort quem trabalha mesmo é a função separe(). Após a lista ser dividida em duas através da pivotação, não ocorrerão mais comparações entre pares de elementos em sublistas diferentes. O Quicksort e mais um exemplo de algoritmos que utiliza a técnica de dividir para conquistar. Em cada nível da recursão do quicksort são realizados três passos:
e d
--+----+----+----+----+----+----+----+----+----+----+--
| 99 | 33 | 55 | 77 | 11 | 22 | 88 | 66 | 33 | 44 |
--+----+----+----+----+----+----+----+----+----+----+--
1. dividir: a função separe() divide a
sublista em sublistas menores
e m d
--+----+----+----+----+----+----+----+----+----+----+--
| 33 | 33 | 22 | 11 | 44 | 55 | 88 | 66 | 99 | 77 |
--+----+----+----+----+----+----+----+----+----+----+--
2. conquistar: as sublistas menores são ordenadas recursivamente
--+----+----+----+----+ +----+----+----+----+----+-- | 11 | 22 | 33 | 33 | | 55 | 66 | 77 | 88 | 99 | --+----+----+----+----+ +----+----+----+----+----+--
3. combinar: as ordenações das sublistas menores são combinadas para obtermos uma ordenação da sublista original
--+----+----+----+----+----+----+----+----+----+----+-- | 11 | 22 | 33 | 33 | 44 | 55 | 66 | 77 | 88 | 99 | --+----+----+----+----+----+----+----+----+----+----+--
Exercícios#
Qual é o número de comparações que são feitas entre elementos das listas pela função
merge_lst(v1,v2)quandov1=[2, 5, 7, 11, 15]ev2=[3]?v1=[3]ev2=[2, 5, 7, 11, 15]?v1=[2, 5, 7, 11, 15]ev2=[3]?v1=[3]ev2=[2, 5, 7, 11, 15]?v1=[3, 6, 8, 10]ev2=[2, 5, 7, 11, 15]?
Baseado nas análises para o consumo de tempo da função
merge(), qual é o consumo de tempo demergesort()no melhor caso e no pior caso para ordenar uma listavcomnelementos? \(\mathtt{\textup{O}(1)}\)? \(\mathtt{\textup{O}(\lg n)}\)? \(\mathtt{\textup{O}(n \lg n)}\)? \(\mathtt{\textup{O}(n^2)}\)? \(\mathtt{\textup{O}(n^3)}\)? \(\mathtt{\textup{O}(2^n)}\)?Baseado nas análises para o consumo de tempo da função
merge(), qual é o consumo de tempo demergesortI()no melhor caso e no pior caso para ordenar uma listavcomnelementos? \(\mathtt{\textup{O}(1)}\)? \(\mathtt{\textup{O}(\lg n)}\)? \(\mathtt{\textup{O}(n \lg n)}\)? \(\mathtt{\textup{O}(n^2)}\)? \(\mathtt{\textup{O}(n^3)}\)? \(\mathtt{\textup{O}(2^n)}\)?Dentre as funções
insercao(),mergesortR(),mergesortI(),quicksortR()equicksortI()qual tem o melhor desempenho para listas aleatórias?Dentre as funções
insercao(),mergesortR(),mergesortI(),quicksortR()equicksortI()qual tem o melhor desempenho para listas crescentes? E para lista quase crescentes que são aquelas que têm poucos elementos fora de suas posições corretas?Dentre as funções
insercao(),mergesortR(),mergesortI(),quicksortR()equicksortI()qual tem o melhor desempenho para listas decrescentes? E para lista quase decrescentes que são aquelas que têm poucos elementos fora de suas posições corretas?Qual é o número de comparações que são feitas pela função
separe_lst(v)entre elementos da lista quandov=[11, 5, 2, 7, 15]?v=[7, 5, 2, 11, 1]?v=[7, 5, 2, 11, 6]?
Baseado nas análises para o consumo de tempo da função
separe(), qual é o consumo de tempo dequicksort()no melhor caso e no pior caso para ordenar uma listavcomnelementos?Baseado nas análises para o consumo de tempo da função
separe(), qual é o consumo de tempo dequicksortI()no melhor caso e no pior caso para ordenar uma sublistavcomnelementos?
Para saber mais#
Mergesort: ordenação por intercalação de Projeto de Algoritmos de Paulo Feofiloff.
Quicksort de Projeto de Algoritmos de Paulo Feofiloff.
O Merge Sort de Resolução de Problemas com Algoritmos e Estruturas de Dados usando Python de Brad Miller e David Ranum.
O Quick Sort de Resolução de Problemas com Algoritmos e Estruturas de Dados usando Python de Brad Miller e David Ranum.
Analysis of Algorithms de Introduction to Programming in Python. de Robert Sedgewick, Kevin Wayne e Robert Dondero.