1.5. Por Que Estudar Estruturas de Dados e Tipos de Dados Abstratos?¶
Para gerenciar a complexidade dos problemas e o processo de resolução de problemas, os cientistas da computação usam abstrações para permitir que se concentrem no corpo principal sem se perder nos detalhes. Criando modelos do domínio do problema, somos capazes de utilizar um melhor e mais eficiente processo de resolução de problemas. Esses modelos nos permitem descrever os dados que nossos algoritmos manipularão de maneira muito mais consistente com respeito ao problema em si.
Anteriormente, nos referimos à abstração procedimental como um processo que oculta os detalhes de uma função específica para permitir que o usuário ou cliente veja de um nível muito alto. Agora voltamos nossa atenção para uma ideia semelhante, o de abstração de dados. Um tipo de dado abstrato, às vezes abreviado ADT (do inglês Abstract Data Type), é uma descrição lógica de como visualizamos os dados e as operações que são permitidas sem considerar como elas são implementadas. Isso significa que estamos preocupados apenas com o que os dados estão representando e não como será eventualmente construído. Fornecendo este nível de abstração, estamos criando um encapsulamento em torno dos dados. A ideia é que encapsulando os detalhes da implementação, estamos escondendo-os da visão do usuário. Isso é chamado de ocultação de informação.
A : ref: Figura 2 <fig_adt> mostra uma imagem de um tipo de dado abstrato e como ele opera. O usuário interage com a interface, usando as operações que foram especificadas pelo tipo de dado abstrato. O tipo de dado abstrato é a capsula com a qual o usuário interage. A implementação é escondida em um nível mais profundo. O usuário não está preocupado com os detalhes da implementação.
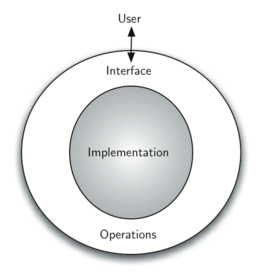
Figure 2: Tipo de Dado Abstrato¶
A implementação de tipos de dados abstratos, geralmente chamado de estruturas de dados, exigirá que forneçamos uma visão física dos dados usando alguma coleção de construções de programação e tipos de dados primitivos. Como discutimos anteriormente, a separação dessas duas perspectivas nos permitirá definir os modelos de dados complexos para os nossos problemas sem dar qualquer indicação quanto aos detalhes de como o modelo realmente será construído. Isso fornece uma visão independente da implementação dos dados. Como normalmente haverá muitas maneiras diferentes de implementar um tipo de dado abstrato, esta independência de implementação permite que o programador mude os detalhes da implementação sem alterar a maneira como o usuário dos dados interage com eles. O usuário pode permanecer focado no processo de resolução de problemas.