2.6. Listas¶
Os desenvolvedores do Python tiveram que tomar muitas decisões quando implementaram as listas. Cada uma dessas decisões poderia ter um impacto no quão rápido as operações sobre listas seriam realizadas. Para ajudá-los a fazer as escolhas certas eles olharam para as maneiras mais comuns como as pessoas utilizariam as listas e então otimizaram a sua implementação de lista para que as operações mais comuns fossem muito rápidas. É claro que eles também tentaram fazer operações menos comuns de maneira eficiente, mas quando a escolha deveria ser feita a performance de uma operação menos comum foi geralmente sacrificada em favor de uma operação mais comum.
Duas operações comuns são o acesso e a atribuição de um elemento através de seu índice. Ambas as operações consomem a mesma quantidade de tempo, independentemente do quão grande a lista se torne. Quando uma operação como essa é independente do tamanho da lista ela é \(O(1)\).
Outra tarefa bastante comum em programação é aumentar uma lista. Há duas
maneiras de criar uma lista mais longa. Você pode usar o método append ou o
operador de concatenação. O método append é \(O(1)\). Entretanto,
o operador de concatenação é \(O(k)\) onde \(k\) é o
tamanho da lista que será concatenada. É importante que você saiba disso
porque escolher a ferramenta certa para o trabalho é importante para
tornar os seus próprios programas mais eficientes.
Vejamos quatro maneiras diferentes de gerar uma lista de n
números começando com 0. Primeiro vamos tentar um laço for e criar uma
lista por concatenação, então usaremos o método append ao invés da concatenação.
Em seguida, vamos tentar criar a lista usando “list comprehension” e finalmente,
e talvez a maneira mais óbvia, usando a função range envolta por uma chamada
ao construtor da lista. Listing 3 mostra o código para
criar a lista de quatro maneiras diferentes.
Listing 3
def teste1():
l = []
for i in range(1000):
l = l + [i]
def teste2():
l = []
for i in range(1000):
l.append(i)
def teste3():
l = [i for i in range(1000)]
def teste4():
l = list(range(1000))
Para calcular o tempo de execução de cada uma das funções utilizaremos
o módulo timeit do Python. O módulo timeit foi criado
para que desenvolvedores Python possam fazer medições de tempo multi-plataforma
executando as funções em um ambiente consistente e usando mecanismos de
medição de tempo similares, dentro do possível, entre sistemas operacionais.
Para usar o timeit você cria um objeto Timer cujos parâmetros são duas
declarações em Python. O primeiro parâmetro é a declaração em Python cujo tempo você
quer medir; o segundo parâmetro é uma declaração que será executada uma vez para
configurar o teste. O módulo timeit medirá então quanto tempo leva a
execução da declaração algumas vezes. Por padrão timeit tentará executar
a declaração um milhão de vezes. Ao terminar ele devolve o tempo como um valor
em ponto flutuante representando o número total de segundos. Entretanto, como ele
executa a declaração um milhão de vezes você pode ler o resultado como o número de
microssegundos para executar o teste uma vez. Você também pode passar para o timeit
um parâmetro nomeado number que permite que você especifique quantas vezes o teste
deve ser executado. A seguir vemos quanto tempo leva para executar cada uma das funções
de teste 1000 vezes.
t1 = Timer("teste1()", "from __main__ import teste1")
print("concatenacao ",t1.timeit(number=1000), "milissegundos")
t2 = Timer("teste2()", "from __main__ import teste2")
print("append ",t2.timeit(number=1000), "milissegundos")
t3 = Timer("teste3()", "from __main__ import teste3")
print("comprehension ",t3.timeit(number=1000), "milissegundos")
t4 = Timer("teste4()", "from __main__ import teste4")
print("range ",t4.timeit(number=1000), "milissegundos")
concatenacao 6.54352807999 milissegundos
append 0.306292057037 milissegundos
comprehension 0.147661924362 milissegundos
range 0.0655000209808 milissegundos
No experimento acima a declaração medida é a chamada das funções teste1(),
teste2(), e assim por diante. A declaração de configuração pode parecer
bem estranha para você, mas vamos considerá-la em mais detalhes. Você provavelmente
está bastante familiarizado com a declaração from, import, mas ela
é usada normalmente no início do arquivo de um programa em Python. Neste caso
a declaração from __main__ import teste1 importa a função
teste1 do namespace __main__ no namespace que o timeit cria para
o experimento de tempo. O módulo timeit faz isso porque ele quer executar
os testes de tempo em um ambiente que é livre de variáveis dispersas que você
pode ter criado, que podem interferir na performance da sua função de algum
modo imprevisto.
Do experimento acima fica claro que a operação de append, com 0,30 milissegundos,
é muito mais rápida do que a concatenação, com 6,54 milissegundos. No
experimento acima nós também mostramos o consumo de tempo de dois métodos
adicionais para a criação de listas; usando o construtor da lista com uma
chamada à função range e usando list comprehension. É interessante notar
que a chamada à list comprehension é duas vezes mais rápida do que um laço
for com uma operação de append.
Uma observação final sobre esse pequeno experimento é que as chamadas de função acima criam uma sobrecarga, mas podemos assumir que a sobrecarga da chamada de função é idêntica em todos os quatro casos, assim ainda temos uma comparação significativa entre as operações. Então não seria acurado dizer que a operação de concatenação leva 6,54 milissegundos, mas que a função de teste da concatenação leva 6,54 milissegundos. Como um exercício você pode testar a quantidade de tempo necessária para chamar uma função vazia e subtrair esse valor dos números acima.
Agora que vimos como a performance pode ser medida de maneira concreta você pode
olhar a Tabela 2 para ver a eficiência em notação O de todas
as operações básicas de listas. Depois de pensar com cuidado sobre a
Table 2, você pode estar se perguntando sobre os dois tempos
diferentes para o pop. Quando pop é chamada no final da lista ela leva
\(O(1)\), mas quando pop é chamada no primeiro elemento da lista
ou qualquer outro elemento no meio ela leva \(O(n)\). A razão para isso está
em como o Python escolhe implementar as listas. Quando um item é retirado da
frente da lista, na implementação do Python, todos os outros elementos na
lista são deslocados uma posição mais próximos do início. Isso pode parecer
bobo para você agora, mas se você olhar para Table 2 você verá
que essa implementação também permite que o acesso ao elemento em um determinado índice seja
\(O(1)\). Essa foi uma escolha que os desenvolvedores do Python pensaram
ser boa.
Operação |
Notação O |
|---|---|
índice [] |
O(1) |
atribuição a índice |
O(1) |
append |
O(1) |
pop() |
O(1) |
pop(i) |
O(n) |
insert(i,item) |
O(n) |
operador del |
O(n) |
iteração |
O(n) |
contém (in) |
O(n) |
fatiar [x:y] |
O(k) |
del fatia |
O(n) |
atribuição a fatia |
O(n+k) |
reverse |
O(n) |
concatenar |
O(k) |
ordenar |
O(n log n) |
multiplicar |
O(nk) |
Como forma de demonstrar essa diferença de performance vamos fazer
outro experimento usando o módulo timeit. Nosso objetivo é sermos capazes
de verificar a performance da operação pop em uma lista de tamanho
conhecido quando o programa executa um pop no final da lista e novamente quando
o pop é executado no início da lista. Nós também queremos medir
esse tempo para listas de tamanhos diferentes. O que você esperaria ver
é que o tempo necessário para realizar o pop a partir do fim da lista se manteria
constante mesmo conforme a lista cresce em tamanho, enquanto o tempo para realizar o pop a partir do
começo da lista continuará a aumentar conforme a lista cresce.
Listing 4 mostra uma tentativa de medir a diferença
entre os dois usos do pop. Como você pode ver no primeiro exemplo,
realizar um pop a partir do fim leva 0,0003 milissegundos, enquanto realizar o pop a partir
do começo leva 4,82 milissegundos. Para uma lista de dois milhões de elementos
esse é um fator de 16.000.
Há algumas coisas a notar sobre Listing 4. A
primeira é a declaração from __main__ import x. Embora nós não
tenhamos definido uma função nós queremos poder utilizar a lista x em nosso
teste. Essa abordagem permite que meçamos o tempo de uma única chamada a pop
e obter a medida mais acurada de tempo para aquela única operação.
Como o cronômetro repete 1000 vezes também é importante lembrar que
a lista está diminuindo de tamanho em 1 a cada iteração do laço. Mas
como a lista inicial possui dois milhões de elementos nós somente reduzimos
o tamanho total em \(0.05\%\).
Listing 4
popzero = timeit.Timer("x.pop(0)",
"from __main__ import x")
popfim = timeit.Timer("x.pop()",
"from __main__ import x")
x = list(range(2000000))
popzero.timeit(number=1000)
4.8213560581207275
x = list(range(2000000))
popfim.timeit(number=1000)
0.0003161430358886719
Enquanto nosso primeiro teste mostra que pop(0) é de fato mais lenta que
pop(), ele não valida a afirmação de que pop(0) é
\(O(n)\) enquanto pop() é \(O(1)\). Para validar essa afirmação
nós precisamos olhar para a performance de ambas as chamadas para um leque
de tamanhos de listas. Listing 5 implementa esse teste.
Listing 5
popzero = Timer("x.pop(0)",
"from __main__ import x")
popfim = Timer("x.pop()",
"from __main__ import x")
print("pop(0) pop()")
for i in range(1000000,100000001,1000000):
x = list(range(i))
pt = popfim.timeit(number=1000)
x = list(range(i))
pz = popzero.timeit(number=1000)
print("%15.5f, %15.5f" %(pz,pt))
A Figura 3 mostra os resultados do nosso experimento. Você pode notar
que conforme a lista se torna maior o tempo necessário para realizar pop(0)
também aumenta enquanto o tempo para pop permanece aproximadamente constante. Isso é
exatamente o que esperaríamos ver para um algoritmo \(O(n)\) e
\(O(1)\).
Algumas fontes de erro em nosso pequeno experimento incluem o fato de existirem outros processos em andamento no computador enquanto medimos o tempo, o que pode reduzir a velocidade do nosso código, assim, mesmo que tentemos minimizar outras coisas acontecendo no computador, obrigatoriamente haverá alguma variação de tempo. Esse é o motivo pelo qual o laço executa o teste mil vezes, para estatisticamente reunir informação suficiente para que a medição seja confiável.
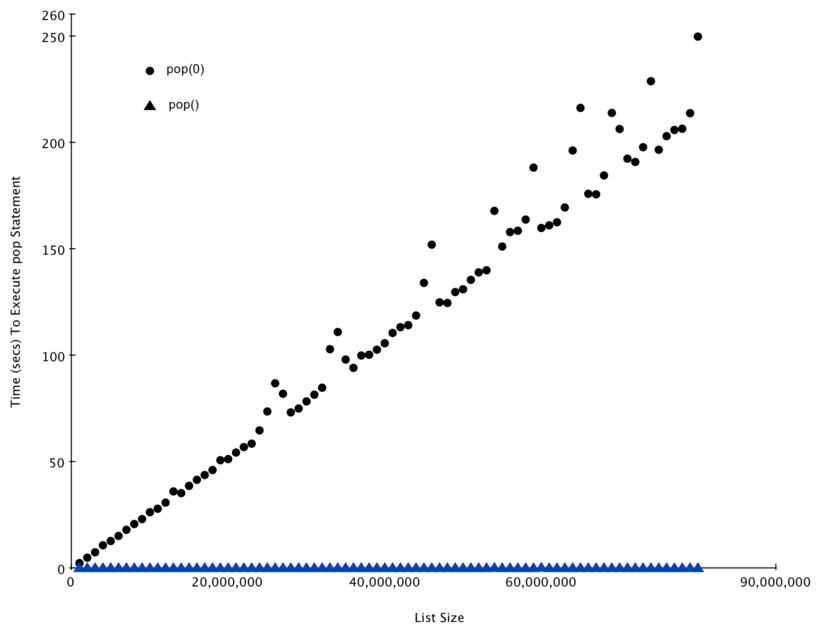
Figura 3: Comparando a Performance de pop e pop(0)¶