Monte Carlo#
Os métodos de Monte Carlo são uma coleção de técnicas computacionais para a solução aproximada de problemas. Esses métodos fazem uso fundamental de amostras aleatórias. Duas classes de problemas estatísticos são mais comumente abordadas dentro desta estrutura: integração e otimização. A metodologia de Monte Carlo também é amplamente utilizada na simulação de sistemas físicos, químicos e biológicos.
Muitos modelos interessantes têm estruturas extremamente complexas e não podem ser facilmente tratados usando técnicas tradicionais. Nesses casos o método de Monte Carlo é um arcabouço computacional para realizarmos inferência estatística.
Objetivos de aprendizagem#
Até aqui, procuramos desenvolver o pensamento computacional aplicado à resolução de problemas. Neste capítulo vamos introduzir o Método de Monte Carlo para realizar simulações computacionais. A simulação computacional pode ser um passo importante no entendimento e modelagem de um problema, antes de chegarmos a uma solução.
Procuraremos entender o processo da simulação para adquirirmos a habilidade para aplicarmos a técnica para possivelmente estimar valores relativos a fenômenos mais complexos para os quais não são conhecidas soluções.
Simularemos alguns fenômenos simples para os quais já conhecemos uma solução, mesmo sendo capazes de chegar a uma solução analiticamente. Nesses casos a simulação pode ser entendida com uma ferramenta importante para comprovar a validade das soluções.
A execução de experimentos aleatórios nas simulações é semelhante à maneira que funcionam jogos de azar, como dados, roletas, … Monte Carlo é uma cidade mundialmente famosa por seus cassinos com seus jogos de azar. Vem daí a razão do nome de batismo do método.
Método de Monte Carlo#
O método de Monte Carlo, ou experimentos de Monte Carlo, são uma ampla classe de algoritmos computacionais que dependem de amostragens aleatórias repetidas para obter resultados numéricos. Usaremos esse método para estimarmos alguns valores.
Da página do curso de Introdução à Computação de Princeton:
Em 1953, Enrico Fermi, John Pasta e Stanslaw Ulam criaram o primeiro “experimento computacional” para estudar uma estrutura atômica vibratória. O sistema não linear não podia ser analisado pela matemática clássica.
A simulação de Monte Carlo usa valores gerados aleatoriamente para variáveis incertas. O método se apoia na lei dos grandes números. Essa lei diz que a média aritmética dos resultados da realização da mesma experiência repetidas vezes tende a se aproximar do valor esperado à medida que mais tentativas se sucederem. Quanto mais tentativas são realizadas, mais a probabilidade da média aritmética dos resultados observados irá se aproximar da probabilidade real.
O método é usado quando outras técnicas falham. Normalmente, a precisão é proporcional à raiz quadrada do número de repetições. Tais técnicas são amplamente aplicadas em vários domínios, incluindo:
projeto de reatores nucleares,
prever a evolução das estrelas,
prever o mercado de ações etc.
Estimando a área de um círculo#
Talvez você esteja pensando “mas para que estimar a área de um círculo se eu já sei calcular a área de um círculo”? Sim, é verdade, sabemos que a área de um círculo de raio \(\mathtt{r}\) é \(\mathtt{\pi r^2}\). Mas, por hora, imagine que você não conhece a fórmula para calcular a área de um círculo. O que você faria para estimar essa área? Nesse primeiro exemplo, vamos ver como aplicar o Método Científico, junto com Monte Carlo, para chegar a uma estimativa da área de um círculo e quão boa ou ruim é essa estimativa.
O método científico está presente em tudo que fazemos cotidianamente. A ideia consiste em
observar algum aspecto da natureza
hipotetizar um modelo consistente com as observações
prever eventos usando as hipóteses
verificar as predições fazendo mais observações
validar repetindo até que hipóteses e observações estejam de acordo
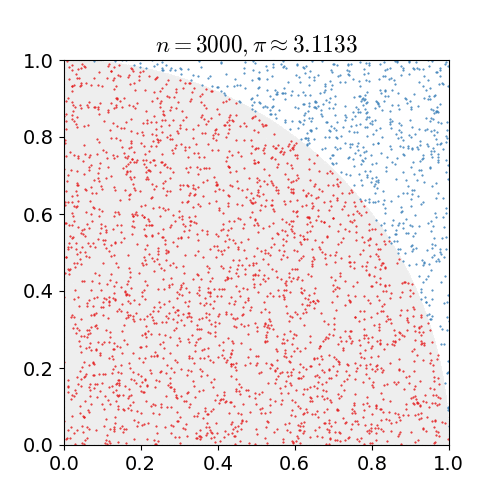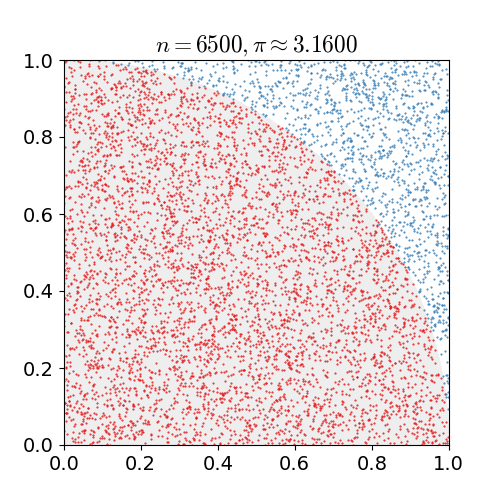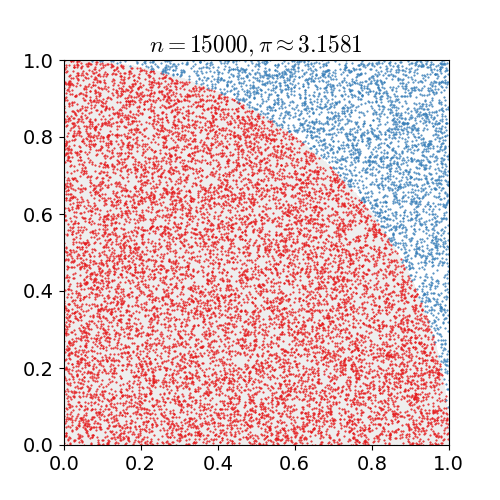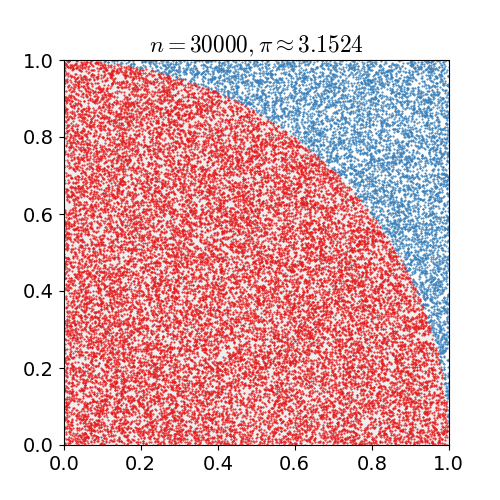
Nosso experimento de Monte Carlo considera a chuva que cai uniformemente ao acaso. A localização de qualquer gota de chuva será interpretada como uma variável aleatória uniformemente distribuída sobre uma região quadrada do espaço com um quadrante do círculo inscrito nesse quadrado, como na imagem a seguir.
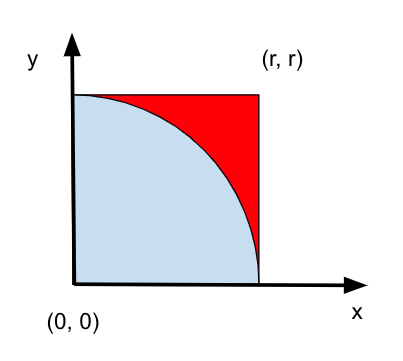
Sem referência a qualquer teoria de probabilidade, é intuitivo que a probabilidade de uma gota de chuva cair em qualquer região dentro do quadrado deve ser proporcional à área dessa região e independe de sua localização. Consequentemente, a probabilidade \(\mathtt{p}\) de que uma gota de chuva esteja dentro do círculo inscrito na imagem acima pode ser expressa como uma relação das áreas do quadrado e do círculo.
No nosso experimentos sortearemos coordenadas (x,y) de pontos que correspondem a posições no quadrante onde uma gota de chuva caiu. Esse sorteio e a quantidade de gotas que caíram na região do círculo pode ser calculada fazendo
x = random.random()*r
y = random.random()*r
if x*x + y*y < r*r: cont += 1
No caso, (x,y) representa a coordenada do ponto e cont será a variável responsável por contabilizar o número total de gotas que caíram no círculo.
Uma breve descrição de algumas funções do módulo random do Python está na seção Aleatoriedade em Python que está mais adiante.
Cada experimento consistirá no sorteio de \(\mathtt{n}\) pontos. A área do círculo será aproximada pela fração \(\mathtt{cont/n}\) de pontos sorteados que caíram no interior do círculo. Sabemos que um quadrado de lados de comprimento \(\mathtt{r}\) tem área \(\mathtt{r^2}\). Assim, se sortearmos \(\mathtt{n}\) pontos, teremos que uma estimativa para a área do círculo pode ser computada fazendo-se \(\mathtt{r^2 \times (cont/n)}\).

A classe Area a seguir será a implementação do laboratório do nosso experimento. Na classe
né o número de pontos a serem sorteados;té o número de experimentospé a média aritmética das áreas obtidas pelostexperimentosmean()é o método que retorna a aproximação da área do circuloexperimento()é o método responsável pela realização de cada experimento.
import random
# número pré-determinado de experimentos
T = 4096
class Area:
#------------------------------------------
def __init__(self, n, t = T, r = 1):
self.n = n # número de pontos usados em cada experimento
self.t = t # número de experimentos
self.raio = r # raio do círculo
area_semicirculo = 0
for i in range(t):
area_semicirculo += self.experimento()
self.p = 4*area_semicirculo/t
#------------------------------------------
def mean(self):
'''(Area) -> float
RETORNA a estimativa experimental da área de um círculo de
raio self.r
'''
return self.p
#-----------------------------------------
def experimento(self):
'''(Area) -> float
SIMULA um experimento sorteando self.n pontos no
quadrante de lado self.r .
RETORNA um estimativa da área do circulo de raio self.r
'''
n = self.n
r = self.raio
if n == 0: return 0
cont = 0
for i in range(n):
x = random.random()*r
y = random.random()*r
if x*x + y*y < r*r: cont += 1
return r*r*(cont/n) # probabilidade de cair no semicírculo.
Realizando alguns experimentos com a classe Area chegamos aos valores mostrados na tabela a seguir.
Todos os experimentos foram realizados com \(\mathtt{n=100}\) e \(\mathtt{t=4096}\).
Baseando-nos nesses resultados experimentais seria razoável propormos o seguinte.
Hipótese. A área do círculo tem a forma \(\mathtt{a r^b}\) para constantes \(\mathtt{a}\) e \(\mathtt{b}\).
Fazendo o gráfico de \(\mathtt{\log \mbox{área}}\) por \(\mathtt{\log r}\), o chamado bilog, se obtivermos uma reta isso indicará que, de fato, a área é uma função da forma \(\mathtt{a r^b}\) e que o coeficiente angular da reta é o valor aproximado para \(\mathtt{b}\). No nosso caso, obtivemos uma reta de coeficiente angular aproximadamente 2.
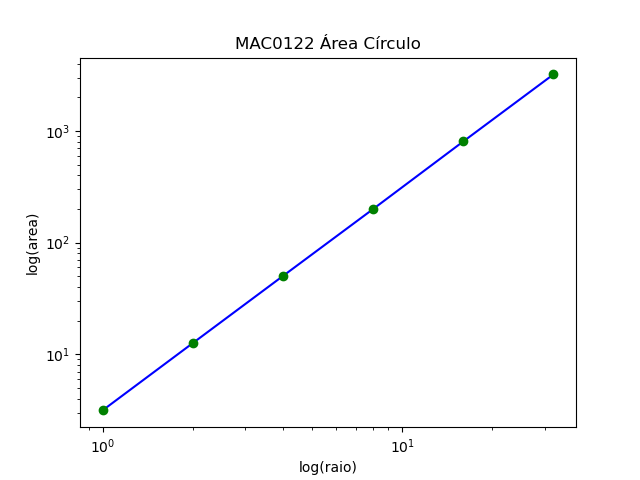
A medida que o raio dobra a área do círculo é multiplicada por 4. Esse fato por si só sugere que o valor de \(\mathtt{b}\) pode ser algo como 2.
Tendo o valor do coeficiente \(\mathtt{b}\) podemos estimar o valor da constante \(\mathtt{a}\) usando a nossa hipótese e os resultados experimentais. Se olharmos na tabela o valor correspondente a \(\mathtt{r = 8}\) obtemos que
Como sabemos, esse valor para \(\mathtt{a}\) é na verdade uma aproximação de \(\mathtt{\pi}\). O erro relativo da nossa estimativa obtida através do método de Monte Carlo foi portanto de aproximadamente:
Nada mal, certo?! 👍🏿 👍🏻 👍🏽 👍🏼 Isso indica que o método tem futuro. 🙂
Paradoxo do Aniversário#
A questão que trataremos agora, que é conhecida como Paradoxo do Aniversário, é a seguinte.
Em uma sala com \(\mathtt{n}\) pessoas, qual é a probabilidade de termos duas ou mais que fazem aniversário em uma mesma data?
Qual a probabilidade desse evento ocorrer quando \(\mathtt{n} = 20\)? E quando \(\mathtt{n} = 40\). Essa probabilidade deve depender do número \(\mathtt{n}\) de pessoas, por isso representaremos essa probabilidade como uma função \(\mathtt{p(n)}\). É evidente que, se \(\mathtt{n}\) é um número maior ou igual ao número de dias em um ano, teremos que \(\mathtt{p(n)=1}\). 😴 Vejamos como o método de Monte Carlo pode nos ajudar a estimar o valor de \(\mathtt{p(n)}\).
Podemos facilmente realizar um experimento com um grupo de amigas e amigos que se encontram para uma festa. 🥮 🎸 🍹 🥂 🧁 🍾 🥤 À medida que o pessoal vai chegando podemos perguntar a data de aniversário de cada uma e de cada um e interromper o experimento, não a festa, assim que descobrirmos duas pessoas que fazem aniversário em uma mesma data.
Será que precisaremos perguntar a data de aniversário a muitas pessoas para encontrar duas que fazem aniversário em uma mesma data? Simularemos esse experimento computacionalmente, já que é mais fácil e rápido e não atrapalha a festa ou encontro algum.
Por simplicidade, na nossa modelagem, ignoraremos pequenas variações na distribuição das datas, tais como anos bissextos, gêmeos, variações sazonais ou semanais.
Suporemos que há 365 datas de aniversários possíveis e que são todas igualmente prováveis.
Representaremos cada data por um inteiro no intervalo range(365).
Um experimento será a simulação do processo de \(\mathtt{n}\) pessoas entrarem na sala.
O resultado do experimento será SUCESSO se houver ao menos duas pessoas na sala com uma mesma data de aniversário na sala,
e será FRACASSO em caso contrário.
Para realizarmos esse experimento de forma computacional podemos representar a sala através de uma lista ou conjunto. Inicialmente essa lista está vazia. Para simular o processo de uma nova pessoa entrar na sala:
sorteamos a data do seu aniversário;
verificamos se a mesma data já foi sorteada antes e, se isso ocorreu, paramos com
SUCESSO;se a data sorteada ainda não ocorreu, acrescentamos a data à lista ou conjunto.
Suponha que DATAS é um apelido para o valor 365.
Para sortearmos uma data basta escrevermos
data = random.randrange(DATAS)
O método de Monte Carlo consiste em executar esse experimento computacional um dado número \(\mathtt{t}\) vezes para deixar a lei dos grandes números fazer a sua mágica.
A estimativa da probabilidade \(\mathtt{p(n)}\) será então o número de experimentos que terminaram em SUCESSO dividido por \(\mathtt{t}\).
Por exemplo, imagine que desejamos estimar \(\mathtt{p(20)}\).
Podemos executar \(\mathtt{t = 1000}\) experimentos e contar o número \(\mathtt{nS}\) de SUCESSO.
A estimativa para \(\mathtt{p(20)}\) será a razão \(\mathtt{nS/t}\).
Agora, como exercício, complete a implementação da classe Aniversario escrevendo o método experimento().
Um possível função main() cliente dessa classe é a seguinte.
A função prob_aniversario() é descrita e apresentada na próxima seção.
def main():
'''
Unidade de teste da classe Aniversario
'''
print("Paradoxo do Aniversário")
print("probabilidade calculada")
p = prob_aniversario(23)
print(f"p({23}) = {p}")
print("probabilidade estimada")
a = Aniversario(23, 1000)
print(f"{a}")
print(f"erro relativo = {abs(a.mean() - p)/p:.2f}")
Descubra quão longe ou quão perto as probabilidades obtidas pelo método de Monte Carlo estão das probabilidade reais.
Aniversário sem simulação#
É possível determinarmos \(\mathtt{p(n)}\) calculando a probabilidade \(\mathtt{q(n)}\) de que todos os \(\mathtt{n}\) aniversários sejam diferentes. Tendo \(\mathtt{q(n)}\) teremos que \(\mathtt{p(n) = 1 -q(n)}\)
Se \(\mathtt{n > 365}\), pelo Princípio da Casa dos Pombos, temos que \(\mathtt{q(n) = 0}\). Por outro lado, se \(\mathtt{n \leq 365}\), ela é dada por
A seguinte função prob_aniversario(n) que se baseia nesses cálculos pode ser utilizada para obtermos alguns valores
de \(\mathtt{p(n)}\).
def prob_aniversario(n):
'''(int) -> float
RECEBE um inteiro n.
RETORNA a probabilidade de em um grupo de n pessoas haja
pelo menos 2 que fazem aniversário em um mesmo dia.
Implementação alternativa:
import math
num = math.factorial(DATAS)
den = math.factorial(DATAS-n)
prob_c = num/(DATAS**n * den)
'''
prob_c = 1
for i in range(n):
prob_c *= (1 - i/DATAS)
return 1 - prob_c
Admiremos alguns valores de \(\mathtt{p(n) = 1 - q(n)}\):
Um fato curioso mostrado nessa tabela é o de que funções injetoras são raras.
Se considerarmos todas as funções de range(24) a range(365) os cálculos que acabamos de fazer mostram que mais da metade delas não são injetoras.
Podemos usar computação para explorar esse problema e obtermos uma aproximação aceitável para \(\mathtt{p(n)}\)? Aqui é que entra o Método de Monte Carlo. O interessante de usarmos o método em um problema que obtivemos a resposta analiticamente é verificar quão boas ou ruins são as aproximações que obtemos com o método.
Colecionador de Figurinhas#
Trataremos agora de um problema bem atual, o problema do(a) colecionador(a) de figurinhas (Coupon collector’s problem). Suponha que temos um álbum com \(\mathtt{n}\) figurinhas que são numeradas de 0 a \(\mathtt{n-1}\). Uma forma de completar o álbum é frequentar lugares onde aficionadas e aficionados por completar o álbum se encontram para trocar figurinhas repetidas por figurinhas que estão faltando no nosso álbum.
Suponha agora que uma colecionadora curiosa deseja saber quantas figurinhas ela precisa comprar para completar seu álbum sem trocar figurinhas repetidas, apenas comprando figurinhas até que o álbum esteja completo. A questão que desejamos tratar é
Quantas figurinhas a colecionadora deve comprar para completar o álbum?
Suporemos que compramos uma figurinha por vez e que cada uma é igualmente provável de ser comprada. Assim, não consideraremos as figurinhas brilhantes como sendo mais difíceis.
Escreveremos uma classe Colecionadora que utiliza o
o método de Monte Carlo para estimar esse número de figurinhas.
A classe Colecionadora recebe dois número inteiros \(\mathtt{n}\) e \(\mathtt{t}\) e realiza \(\mathtt{t}\) experimentos aleatórios.
Em cada experimento a Colecionadora conta o número de figurinhas que teve comprar para preecher um álbum de \(\mathtt{n}\) figurinhas.
Com esses números em mãos a Colecionadora estima o número de figurinhas que devem ser compradas para completar o álbum.
A cada instante uma figurinha dentre as \(\mathtt{n}\) possíveis é comprada com a mesma probabilidade. O adjetivo aleatório dos experimentos é devido a essa tal probabilidade. A compra de cada figurinha se assemelha ao lançamento de um dado honesto de \(\mathtt{n}\) faces. Hãã?!. 😵 A face que fica para cima após o lançamento é o número da figurinha comprada.
Por exemplo, suponha que tenhamos um álbum de \(\mathtt{n = 5}\) figurinhas e que a Colecionadora deve realizar \(\mathtt{t = 3}\) experimentos.
A sequência de figurinhas compradas no primeiro experimento pode ser
4 0 1 1 1 1 4 3 0 1 1 0 2em que as novas figurinhas adquiridas estão em vermelho.
Nesse primeiro experimento a Colecionadora teve que comprar \(\mathtt{f_0 = 13}\)
figurinhas até completar o álbum de \(\mathtt{n = 5}\) figurinhas.
As figurinhas têm número 0, 1, 2, 3, e 4, certo?!
No segundo experimento as figurinhas compradas poderiam ter sido
4 3 0 2 1 Uau! 🎆 A Colecionadora comprou exatamente \(\mathtt{f_1 = 5}\) figurinhas para completar o álbum.
Finalmente, já que \(\mathtt{t = 3}\), a Colecionadora precisa realizar apenas um último experimento.
Suponha que desta vez a ordem das figurinhas compradas seja
3 3 3 3 4 3 2 0 4 0 1Desta vez foram compradas \(\mathtt{f_2 = 11}\) figurinhas para completar o álbum.
Antes de terminar o seu serviço e poder ir para casa a Colecionadora calcula o número médio de figurinhas compradas nos \(\mathtt{t = 3}\) experimentos.
Esse número é \(\mathtt{F = (f_0 + f_1 + f_2)/3 = (13 + 5 + 11)/3 = 9{,}66...}\).
A Colecionadora declara que \(\mathtt{9.66...}\) é o número estimado de figurinhas que devem ser compradas para preencher um álbum de 5 figurinhas,
fecha o laboratório e vai para casa descansar.
Não se aborreça com o fato de \(\mathtt{9.666}\) não ser um número inteiro.
Ele é apenas um estimador fazendo o seu trabalho de estimar.
Um exemplo de cliente da classe Colecionadora é a seguinte função main().
A função no_figurinhas() é descrita e apresentada na próxima seção.
def main():
'''
Unidade de teste da classe Colecionadora
'''
print("Colecionadora de Figurinhas")
print("número de figurinhas calculado")
n = no_figurinhas(400)
print(f"f({400}) = {n}")
print("número de figurinhas estimado")
colecionadora = Colecionadora(400, 100)
print(f"{colecionadora}")
print(f"erro relativo = {abs(colecionadora.mean() - n)/n:.2f}")
Na classe Colecionadora que está a seguir ficou como exercício implementar o método experimento().
Figurinhas sem simulação#
É possível determinarmos diretamente o número esperado de figurinhas que a colecionadora deve comprar para completar o album.
Seja \(\mathtt{T}\) o número de figurinhas a serem compradas para completarmos um álbum. Seja \(\mathtt{t_i}\) o número de figurinhas que compramos entre obtermos a \(\mathtt{(i-1)}\)-ésima e a \(\mathtt{i}\)-ésima figurinha distinta. \(\mathtt{T}\) e \(\mathtt{t_i}\) são variáveis aleatórias e \(\mathtt{T = t_1 + t_2 + \cdots + t_n}\). A probabilidade \(\mathtt{p_i}\) de conseguirmos uma figurinha distinta, dado que já conseguimos \(\mathtt{i-1}\) figurinhas distintas é \(\mathtt{(n - (i-1))/n}\). Seja \(\mathtt{q_i = 1 - p_i = 1/(i-1)}\). Assim, o valor esperado de \(\mathtt{t_i}\) é dado por
Desta forma, temos que
em que \(\mathtt{H_n}\) é o \(\mathtt{n}\)-ésimo número harmônico.
Portanto, temos que comprar aproximadamente \(\mathtt{n \ln n}\) figurinhas para completarmos um album de \(\mathtt{n}\), supondo que a probabilidade … Para um album de 400 figurinhas é esperado que tenhamos que comprar cerca de 2400 figurinhas.
A seguinte função no_figurinhas() calcula e retorna o número esperado de figurinhas a serem compradas.
def no_figurinhas(n):
'''(int) -> float
RECEBE um inteiro.
RETORNA o número esperado de figurinhas que devem ser compradas para
completarmos um álbum de n figurinhas.
'''
hn = 0
for i in range(n,0,-1): hn += 1/i
return n*hn
Urnas eletrônicas#
Suponha que em uma população de 100 milhões de eleitoras e eleitores, 51% votaram para a(o) candidata(o) A e 49% votaram para a(o) candidata(o) B.
Na votação foi utilizada uma urna eletrônica que é propensa a contabilizar 5% dos votos de maneira errada.
Quando erra a urna troca a(o) candidata(o) que recebeu o voto.
Se um voto foi para A, a urna contabiliza para B e se o voto foi para B, ela contabiliza para A.
Problema. Supondo que os erros ocorrem uniformemente ao acaso, 5% é uma porcentagem de erro suficiente para que seja provável, digamos que com mais de 50%, 25%, 10% ou 5% de chance, que o resultado da eleição tenha sido alterado? Qual porcentagem de erro poderia ser tolerada para que, digamos com mais de 95% de certeza, não haja alteração no resultado?
Há certamente várias questões aqui que despertam paixões e que são associadas a problemas similares, afinal, 1% de incerteza ainda é incerteza. Nos concentraremos em aspectos que podem ser investigados através do Método de Monte Carlo. Está seção é baseada no exercício 5 do Capítulo 2 do livro Computer Science: An Interdisciplinary Approach .
Modelagem é a procura por uma representação que aproxime de maneira satisfatória um fenômeno real que é difícil de observar diretamente. Modelos são usados para explicar e prever o comportamento de sistemas reais e são aplicados em uma variedade de atividades do dia a dia. Embora a modelagem seja um componente central da ciência, os modelos, na melhor das hipóteses, são aproximações dos sistemas que representam, não são réplicas exatas. Todas e todos estão constantemente trabalhando para melhorar e tornar os modelos mais satisfatórios e úteis.
Na nossa modelagem da Eleição um componente central será a aleatoriedade: suporemos que os erros na contabilização dos votos ocorrerão uniformemente ao acaso. Isso significa que cada voto poderá ser contabilizado erroneamente com a mesma probabilidade. Por exemplo, suponha que nossa eleição tenha 20 votos e esses votos sejam
A B B A B A A B A B A A B A B B A A A B Nessa eleição A venceu já que obteve 11 votos ante 9 votos recebidos por B.
Se as urnas eletrônicas 20% das vezes contabilizam erroneamente um voto, então nessa eleição de 20 votos teremos
\(\mathtt{20 \times 0.2 = 4}\) votos que serão contabilizados erroneamente.
Assim, uma contabilização possível dos votos com erros poderia ser
A B B B B A A B A A A A B A A B A A A A em que os votos em vermelho são aqueles contabilizados de forma errada.
Como podemos ver, nesse caso o resultado da eleição não foi alterado, foram contabilizados 13 votos para A e 7 votos para B.
Uma outra contabilização possível poderia ser
A B B A B B A B A B B A B B B B A B A A e nessa o resultado da eleição foi alterado, B passou a vencer por 12 votos a 8.
A fim de obter uma estimativa para a probabilidade do resultado da eleição ser alterado escreveremos uma classe Eleicao
que realiza experimentos de Monte Carlo.
A estrutura da classe Eleicao é semelhante a das classes Area, Aniversario e Colecionadora que fizemos.
O construtor da classe recebe como argumentos:
no_votos: um inteiro com o número total de votos em um da(o)s dois candidata(o)s;votos_A: um inteiro que é número de votos recebidos pela(o) condidada(o)A;erro: um inteiro com porcentagem de votos contabilizados erroneamente;t: um inteiro que indica o número de experimentos que devem ser realizados
A classe supõe que a(o) candidata(o) A foi a(o) vencedora(or) da eleição, votos_A > no_votos/2.
Para estimar a probabilidade, um objeto da classe Eleicao realizará t experimentos.
Se k é o número de experimentos em que o resultado da eleição foi alterado, a(o) candidata(o) B passou a ser a(o) vencedor(a) ou chegamos a um empate,
então o objeto deve retornar através de um método prob() a razão \(\mathtt{k/t}\).
Abaixo está um exemplo de cliente da classe Eleicao:
# constantes para a eleição
NO_VOTOS = 100000000 # número total de votos
VOTOS_A = 51000000 # número de votos em A
VOTOS_B = NO_VOTOS - VOTOS_A # número de votos em B
ERRO = 5 # porcentagem de erro
T = 10 # número de experimentos
## ==================================================================
#
def main():
'''
Testes das classes Eleicao
'''
# teste eleição
print("Experimentos da classe Eleicao")
eleicao = Eleicao(NO_VOTOS, VOTOS_A, 2, T) # 2% de erro
print(f"Eleicao(v={NO_VOTOS},a={VOTOS_A},e={2},t={T})={eleicao.prob()}")
print(f"{Eleicao(no_votos=NO_VOTOS, votos_A=VOTOS_A, erro=ERRO, t=T)}") # 5% de erro
print(f"{Eleicao(no_votos=NO_VOTOS, votos_A=VOTOS_A, erro=10, t=T)}") # 10% de erro
print(f"{Eleicao(no_votos=NO_VOTOS, votos_A=VOTOS_A, erro=20, t=T)}") # 20% de erro
print(f"{Eleicao(no_votos=NO_VOTOS, votos_A=VOTOS_A, erro=30, t=T)}") # 30% de erro
A saída esperada produzida por essa função main() terá a forma:
Experimentos da classe Eleicao
Eleicao(v=100000000,a=51000000,e=2,t=10)=?.?
Eleicao(v=100000000,a=51000000,e=5,t=10)=?.?
Eleicao(v=100000000,a=51000000,e=10,t=10)=?.?
Eleicao(v=100000000,a=51000000,e=20,t=10)=?.?
Eleicao(v=100000000,a=51000000,e=30,t=10)=?.?
Em que as ?.? representam as probabilidades estimadas pelos experimentos.
A sua implementação da classe Eleicao será deixada como exercício.
Depois de realizar os experimentos, procure verificar se a estimativa da
probabilidade do resultado da eleição ser alterado parece razoável.
Procure produzir uma argumentação que justifique o comportamento observado.
Se não for possível produzir uma tal argumentação talvez o experimento esteja errado.
De qualquer forma, fazer mais experimentos pode dar uma luz sobre o fenômeno e sobre o que esperar.
É desejável que os experimentos possam ser realizados várias vezes.
O número de vezes que um experimento é realizado está por conta do parâmetro t dos objetos da classe Eleição.
Se um objeto da classe Eleicao estiver fazendo o seu serviço muito lentamente há algumas coisas que podem ser tentadas para acelerá-lo.
Como fizemos em 14. Operações com imagens podemos apelar para NumPy.
Frequentemente os comandos de repetições são chamados simplemente de laços ou loops.
Objetos numpy.ndarrays permitem que troquemos o uso de laços que manipulam seus elementos um a um chamadas operações vetoriais.
Essa técnica é conhecida pelo nome de vetorização.
Seguem alguns exemplos em que laços como while ..., for ... são substituídos por operações vetoriais que são muito mais eficiente.
No que segue ar1 é um objeto numpy.ndarray, um array.
Por isso quando escrevemos ar1 > 4 teremos um novo numpy.ndarray de dtype=bool e com o mesmo shape de ar1.
Nesse novo numpy.ndarray temos que cada posição de índice i é True se ar1[i] > 4 é False se ar1[i] <= 4:
In [4]: import numpy as np
In [5]: lst = [ 1, 6, 7, 2, 6, 5, 3]
In [6]: ar1 = np.array(lst)
In [7]: ar1
Out[7]: array([1, 6, 7, 2, 6, 5, 3])
In [8]: ar1 > 4 # isto um exemplo de vetorização
Out[8]: array([False, True, True, False, True, True, False])
Se desejarmos saber o número de True no array ar1 > 4 podemos fazer
In [9]: ar2 = ar1 > 4
In [10]: np.sum(ar2) # o resultado é o número de True em ar2
Out[10]: 4
Na adição feita pela função np.sum() tudo se passa como se True fosse 1 e False fosse 0.
Para gerarmos um numpy.ndarray com uma amostra aleatória de 3 números inteiros em range(5) podemos usar a função np.random.choice() e escrever
In [13]: np.random.choice(5, 3, replace=False) # gera uma amostra aleatória de np.arange(5) sem repetições
Out[13]: array([2, 0, 4])
O argumento replace=False indica que a amostra será criada sem repetições. Sem esse argumento a amostra poderá ter elementos repetidos:
In [15]: np.random.choice(5, 3) # gera uma amostra aleatória de range(5) com possíveis repetições
Out[15]: array([4, 2, 2])
In [16]: np.random.choice(5, 3) # gera uma amostra aleatória de range(5) com possíveis repetições
Out[16]: array([3, 1, 0])
Para simularmos 6 lançamentos de uma moeda em que a probabilidade de cara é p=0.3 e de coroa 0.7 podemos utilizar a função np.random.binomial() e escrevemos:
In [56]: np.random.binomial(n=1, p=0.3, size=6)
Out[56]: array([1, 1, 1, 0, 0, 1])
Neste exemplo estamos interpretando 1 como cara e 0 como coroa.
Para termos o número de caras ou de coroas na amostra podemos fazer:
In [57]: lances = np.random.binomial(n=1, p=0.3, size=6)
In [58]: lances
Out[58]: array([0, 0, 1, 0, 0, 0])
In [59]: caras = np.sum(lances == 1)
In [60]: coroas = np.sum(lances==0)
In [61]: caras
Out[61]: 1
In [62]: coroas
Out[62]: 5
O número de caras em 20000 lançamentos de uma moeda em que a probabilidade de cara é 0.1 pode ser simulado com
In [84]: np.sum(np.random.binomial(1, 0.1, 20000) == 1)
Out[84]: 2057
Aleatoriedade em Python#
Em Python temos a classe random com vários métodos e funções para gerarmos objetos aleatoriamente.
Veja a página Generate pseudo-random numbers.
Entre esses métodos e funções temos alguns que já usamos:
random.seed(a=None, version=2): inicializa o gerador de números aleatóriosrandom.randrange(start, stop[, step]): retorna um valor escolhido uniformemente ao acaso emrange(start, stop[,step])random.choice(lst): retorna um item escolhido uniformemente ao acaso da listalst.random.shuffle(lst[, random]): embaralha in place os itens na listalst.random.sample(populacao, k): retorna uma lista comkelementos dapolulacaoque é um objeto da classelistouset
In [1]: import random
In [2]: random.seed("oi")
In [3]: random.randrange(27)
Out[3]: 7
In [4]: random.seed("oi")
In [5]: random.randrange(27)
Out[5]: 7
In [6]: random.seed("Eduardo")
In [6]: random.randrange(27)
Out[6]: 14
In [7]: lst = ["joão", "pedro", "juliana", "giovana", "julia"]
In [8]: random.choice(lst)
Out[8]: 'giovana'
In [9]: random.choice(lst)
Out[9]: 'julia'
In [10]: random.choice(lst)
Out[10]: 'julia'
In [11]: random.choice(lst)
Out[11]: 'pedro'
In [12]: lst
Out[12]: ['joão', 'pedro', 'juliana', 'giovana', 'julia']
In [13]: random.shuffle(lst)
In [14]: lst
Out[14]: ['julia', 'juliana', 'pedro', 'giovana', 'joão']
In [15]: random.shuffle(lst)
In [16]: lst
Out[16]: ['giovana', 'joão', 'pedro', 'juliana', 'julia']
In [17]: random.sample(lst,2)
Out[17]: ['giovana', 'julia']
In [18]: random.sample(lst,2)
Out[18]: ['juliana', 'pedro']
In [19]: random.sample(lst,2)
Out[19]: ['joão', 'julia']
Eficiência de set#
Python possui o tipo nativo set que permite a criação e manipulação de conjuntos.
Um conjunto é uma coleção não ordenada sem elementos duplicados. Os usos básicos incluem testes de adesão e eliminando entradas duplicadas. Objetos da classe conjunto admitem operações como união, intersecção, diferença e diferença simétrica.
Internamente, para o Python, conjuntos são dicionários em que o valor associado a cada chave é irrelevante, apenas as chaves, elementos do conjunto, importam. Por essa razão, de maneira semelhante ao que ocorre com dicionário, os elementos de um conjunto em Python devem ser objetos imutáveis como números, strings e tuples.
Para se criar um conjunto vazio podemos escrever
In [2]: s = {}
Chaves ou a função set() podem ser usadas para criar conjuntos.
Para criar um conjunto vazio devemos usar set() e não {}, já que
o par de chaves {} é usado para criar um dicionário vazio.
In [1]: s = set('abracadabra')
In [2]: t = set('alacazam')
In [3]: s
Out[3]: {'a', 'r', 'b', 'c', 'd'}
In [4]: s - t # letras em s mas não em t
Out[4]: {'r', 'd', 'b'}
In [5]: s | t # letras em s ou em t ou em ambos
Out[5]: {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
In [6]: s & t # letras em ambos s e t
Out[6]: {'a', 'c'}
In [7]: s ^ t # letras em s ou em t
Out[7]: {'r', 'd', 'b', 'm', 'z', 'l'}
O comportamento básico de objeto do tipo set também ilustrado pelo trecho de código abaixo.
def main():
# crie um conjunto vazio
conj0 = set()
print(f' 1: conj0: {conj0} tem tamanho {len(conj0)}')
# crie um conjunto e obeserve que não há ordem entre os elementos de um conjunto
conj1 = { 'set', "e'", (2,2), 'da hora', '!!' }
print(f' 2: conj1: {conj1} tem tamanho {len(conj1)}')
# use o método add() para inserir elementos em um conjunto
for i in range(5):
conj0.add( (i, 2) )
print(' 3: conj0:', conj0)
# use o método union() para unir conjuntos
print(' 4: uniao:', conj0.union(conj1))
# use o método intersection() para determinar a intersecção de conjuntos
print(' 5: intersecção:', conj1.intersection(conj0))
# uso de 'for ... in ...' para percorrer os elementos de um conjunto.
for elemento in conj0:
# testa se elemento é um elemento de conj1
if elemento in conj1:
print(f" >>> {elemento} pertence a {conj1}")
else:
print(f" x {elemento} não pertence a {conj1}")
A função main() produz a saída a seguir.
Examinar a função main() e o seu comporatmento pode ser instrutivo para compreender o funcionamento de objetos da classe set.
1: conj0: set() tem tamanho 0
2: conj1: {'!!', 'set', (2, 2), 'da hora', "e'"} tem tamanho 5
3: conj0: {(1, 2), (4, 2), (0, 2), (2, 2), (3, 2)}
4: uniao: {(1, 2), (4, 2), (0, 2), '!!', 'set', (2, 2), 'da hora', (3, 2), "e'"}
5: intersecção: {(2, 2)}
x (1, 2) não pertence a {'!!', 'set', (2, 2), 'da hora', "e'"}
x (4, 2) não pertence a {'!!', 'set', (2, 2), 'da hora', "e'"}
x (0, 2) não pertence a {'!!', 'set', (2, 2), 'da hora', "e'"}
>>> (2, 2) pertence a {'!!', 'set', (2, 2), 'da hora', "e'"}
x (3, 2) não pertence a {'!!', 'set', (2, 2), 'da hora', "e'"}
Agora vamos aos consumos de tempo.
Suponha que o dicionário s e t são conjuntos x é um objeto imutável qualquer.
A função len() quando usada com um objeto da classe set retorna o número de elementos no conjunto.
A tabela foi copiada de TimeComplexity.
Lições#

Uma das lições que aprendemos com nesses experimentos é que vale a pena trocar figurinhas repetidas para completar álbuns. Vale a pena significa que apenas comprar figurinhas para completar um album sai muito caro. Se bem que isso já era intuitivo. Não era necessário o Método de Monte Carlo para chegarmos a essa conclusão.
O ponto é que, frequentemente, devido à complexidade envolvida na obtenção de resultados exatos através de modelos analíticos, as simulações computacionais do Método de Monte Carlo são ferramentas muito úteis para estimarmos algum valor de interesse. A simulação deve ser minimamente eficiente para que obtenhamos estimadores sem termos que esperar até o final dos tempos. Para tornar as simulações efetivas entram em campo várias atrizes e atores como biologia, computação, estatística, engenharia, física, matemática,… todas e todos trabalhando lado a lado.
Os programas que consideramos ao longo do ano são um ponto de partida, não um estudo completo. Esta disciplina também é um ponto de partida para o seus estudos posteriores em ciências ou engenharias. A abordagem de programação (computational thinking) e as ferramentas que você aprendeu devem auxiliá-la(o) a resolver vários problemas computacionais que serão encontrados no restante de seu curso e na vida profissional.