
2. O que é uma imagem gerada por computador?#
A computação gráfica se preocupa com tudo que envolve a geração de imagens por computador. Nessa aula vamos apresentar, com mais detalhes, o processo de formação de imagens a partir do padrão de luz que estimula nossos olhos até as formas usadas para representar essas imagens.
Recomendamos a leitura a seguir para complementar essas notas.
Capítulo 1 do livro “Interactive Computer Graphics” de Edward Angel; e/ou:
2.1. Formação de Imagens#
As imagens geradas por computação gráfica são sintéticas (ou artificiais), ou seja, os objetos mostrados nas imagens não são “reais”! A imagem desses objetos precisam ser geradas a partir de “modelos”. Para isso, há vários aspectos que precisamos conhecer como cor, iluminação e a interação da luz com as superfícies dos objetos. Quanto mais detalhadas forem essas informações, mais “realistas” serão as imagens que podemos gerar. Os principais elementos 3D que vamos considerar nesse curso estão ilustrados na Figura Fig. 2.1.

Fig. 2.1 Elementos que contribuem para a formação de uma imagem.#
A luz emitida por uma fonte de luz e que chega à câmera depende de propriedades das superfícies dos objetos e da câmera (ou olho da pessoa observando a cena). Vamos discutir alguns desses elementos com mais detalhes nas seções seguintes.
A presenças de outras fontes de luz e fenômenos como reflexões múltiplas entre objetos e a influência do meio onde a luz se propaga, são apenas alguns elementos que podem melhorar a qualidade desse modelo e que não estão ilustrados na figura.
2.2. Luz e percepção de cor#
Uma propriedade básica da luz é sua cor. A luz visível, quando considerada como onda eletromagnética, tem comprimento de onda no intervalo entre 400 nm a 750 nm que corresponde às cores do violeta ao vermelho e, basicamente, cobre o espectro de cores como vemos em um arco-íris.
Nossa percepção de cor no entanto é um fenômeno mais complexo. Observe que a cor “branca”, por exemplo, corresponde a nossa percepção de cor quando o olho é estimulado por radiação composta por todos esses comprimentos de onda juntos. Isso ocorre devido a fisiologia do olho, como ilustrado na Figura Fig. 2.2.
A córnea é uma membrana externa transparente que protege o olho e permite a entrada de luz. A córnea basicamente cobre a íris, a parte colorida do olho, que tem uma abertura no centro chamada de pupila. A pupila muda de tamanho constantemente para regular a quantidade de luz que chega à retina, que é uma camada de células foto sensíveis depositada no fundo do olho. A fóvea é uma região na retina que concentra os cones, que são células foto sensíveis responsáveis pela visão cromática. Há 3 tipos de cones, cada um sensível a um determinado comprimento de onda, denominados cone\(_R\), cone\(_G\) e cone\(_B\), pois respondem aos comprimentos de onda R (de red, ou vermelho), G (de green ou verde) e B (de blue ou azul). Não é a toa que os monitores coloridos são construídos para gerar estímulos tricromáticos RGB e é por isso também que a representação mais comum de imagens coloridas segue esse padrão.
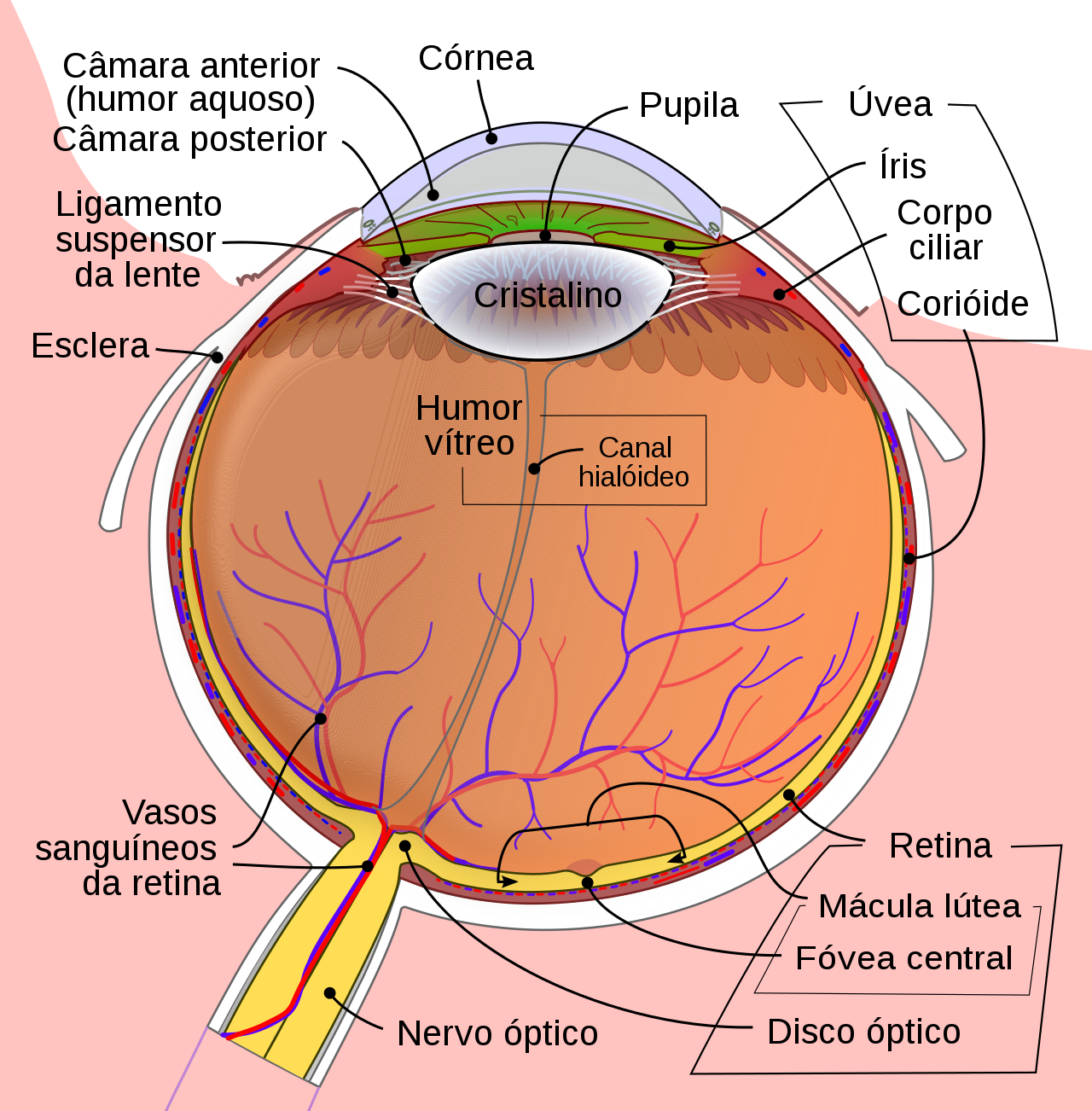
Fig. 2.2 Diagrama do olho humano. Imagem reproduzida da Wikipedia..#
2.3. Objetos da cena e suas propriedades#
Uma forma computacionalmente eficaz para representar a forma de objetos é por meio de elementos geométricos primitivos como pontos (vértices) e linhas. As superfícies podem ser decompostas em polígonos simples, como triângulos, que podem ser definidos por um conjunto de vértices. Curvas e superfícies complexas, como um disco ou esfera, podem ser aproximadas usando um número suficientemente grande de linhas ou triângulos. O processo de modelar objetos ainda mais complexos, como uma face humana, a partir desses elementos geométricos básicos não é simples e, por isso, existem várias ferramentas especializadas que facilitam a construção desses modelos como o Blender. No entanto, o uso dessas ferramentas não faz parte do escopo desse curso e, por isso, vamos nos limitar a objetos mais simples de modelar para que possamos focar no processo de renderização desses modelos.
Vale aqui observar que a escolha de usar apenas elementos geométricos primitivos é a eficiência computacional para gerar essas imagens usando processadores gráficos modernos, que são otimizados para processar esses elementos. Processar elementos mais complexos é certamente possível mas tornaria a arquitetura desses processadores mais complexa também. Ao invés disso, há várias bibliotecas gráficas que podem ser usadas para simplificar o processo de modelagem de objetos.
Além da forma, cada objeto possui propriedades que precisam ser representadas no modelo como:
cor,
opacidade,
brilho,
rugosidade, etc.
Veremos em aulas futuras que algumas dessas propriedades podem ser associadas a superfícies, como texturas, ou ainda associadas a cada vértice, como cor.
2.4. Câmera, Olho ou Observador#
A criação de filmes de animação requer a geração de desenhos para cada quadro. Por exemplo, cerca de 750 artistas participaram da produção do filme “Branca de Neve e os Sete Anões”, dos estúdios da Disney. Em um período de 3 anos o grupo criou mais de 2 milhões de rascunhos até a versão final do filme, lançado em 1937, e que era composto por mais de 250 mil imagens distintas.
A geração de imagens por computador considera uma cena 3D, previamente modelada, e o posicionamento de uma câmera virtual, como se quiséssemos tirar uma foto da cena. Além da posição e orientação dessa câmera virtual, a imagem resultante depende ainda de outros parâmetros, como resolução da imagem, nível de zoom da lente, abertura da lente, etc. A animação é feita alterando esses parâmetros que controlam a câmera e também atualizando o estado dos objetos que constituem a cena.
Vamos utilizar o modelo de câmera pinhole que recebe esse nome (buraco de agulha) por poder ser construída a partir de uma caixa que tem um buraquinho por onde a luz entra e sensibiliza o filme fotográfico ou sensor eletrônico colocado no lado oposto. Esse é um modelo simples de câmera que não possui lente e que nos permite modelar a projeção dos objetos no plano da imagem. A Figura Fig. 2.3 ilustra as principais características de uma câmera pinhole.
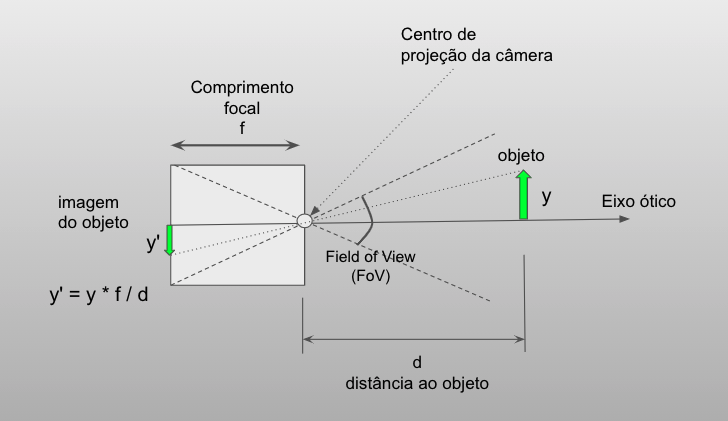
Fig. 2.3 Câmera pinhole#
Considere a caixa como um paralelepípedo com um pequeno buraco em uma das faces por onde a luz penetra na caixa. O buraco define o ponto chamado de Centro de Projeção (CP) da câmera. O eixo ótico da câmera é definido pelo vetor que passa por CP e é perpendicular ao plano da imagem. O plano da imagem contém a face oposta à face que contém CP. Na prática, o filme fotográfico ou sensor eletrônico é colocado nesse plano para receber a luz que entra na câmera pelo pinhole.
A altura de um ponto (ou objeto) distante \(d\) do centro de projeção é medida perpendicularmente ao eixo ótico. A figura mostra um objeto de altura \(y\) e a imagem desse objeto \(y' = y * f / d\). A distância do centro de projeção ao plano da imagem é chamado de comprimento focal (\(f\)) da câmera.
Outro parâmetro importante é o campo de visão (field of view ou FoV) que pode ser definido pelas dimensões da caixa. Como o sensor em geral é retangular, podemos definir um FoV vertical e outro horizontal. Assim, para um sensor de largura \(W\) e altura \(H\) o FoV vertical pode ser calculado como: \(FoV_v = 2 atan(H/(2*f))\).
Por fim, a razão \(W / H\) da câmera (ou sensor ou ainda da imagem) define a sua razão de aspecto (aspect ratio).
Como a câmera pinhole não usa lentes, ela possui campo de profundidade (depth of field) infinito, ou seja, todos os pixels da imagem ficam “em foco”. No entanto, isso só é possível pois, como o buraco é muito pequeno, apenas raios de luz provenientes de uma única direção estimulam um ponto na imagem, o que pode ser uma desvantagem pois pouca luz penetra na câmera. Outra desvantagem é que, para modificar o nível de zoom, é necessário modificar fisicamente a distância da imagem ao buraco (comprimento focal), o que modifica também o FoV.
É importante você conhecer esse modelo e conceitos para entender, em aulas futuras, como representar a projeção na forma de uma transformação linear e obter a imagem dos objetos.
2.5. Representação de imagens#
A forma mais comum de representar uma imagem é por meio de uma matriz de pixels. Essa representação é conhecida como imagem raster. O número de pixels na matriz define a resolução da imagem. Por exemplo, a resolução padrão full HD usada para monitores e TVs corresponde a \(1920 \times 1080\) pixels. Quando trabalhamos com imagens digitais, a primeira dimensão costuma indicar o número de colunas (1920) e a segunda dimensão o número de linhas (1080) da imagem. Observe no entanto que, na álgebra linear e na computação, as coordenadas de um elemento de uma matriz são dadas na ordem (linha, coluna), o que pode causar alguma confusão mais tarde.
Além da resolução, cada pixel de uma imagem tem uma certa profundidade, como ilustrado na Figura Fig. 2.4. A profundidade de uma imagem binária é um bit. Usando apenas 1 bit que pode assumir os valores 0 ou 1, podemos representar que um pixel esteja apenas em dois estados como ligado ou desligado, ou ainda acesso ou apagado, branco ou preto, etc.
Uma imagem em níveis de cinza tipicamente possui 8 bits (que equivale a 1 byte) de profundidade. Com isso, é possível representar \(2^8 = 256\) níveis de cinza. Mais bits podem ser utilizados para representar imagens com grande variação dinâmica entre o pixel mais claro e o mais escuro.
Uma imagem colorida é tipicamente representada usando 3 ou 4 bytes por pixel. Na representação RGB cada pixel é representando usando as 3 cores primárias: vermelho (red), verde (green) e azul (blue). Um byte é utilizado para quantificar a contribuição de cada uma dessas componentes de cor, no total de \(3\times8 = 24\) bits.

Fig. 2.4 Imagem binária com profundidade de 1 bit, imagem com 256 níveis de cinza com profundidade 8 bits e imagem colorida RGB com profundidade 24 bits (8 bits por canal de cor).#
O método escolhido para representar a cor também depende das características do dispositivo de saída gráfica e da aplicação. Por exemplo, monitores combinam as componentes RGB provenientes de fontes de luz de forma aditiva, enquanto os pigmentos usados em impressoras são combinados de forma subtrativa. Em muitos sistemas gráficos, é comum adicionar um quarto componente, às vezes chamado de alfa e denotado por A (em RGBA). Esse componente pode ser usado para obter vários efeitos especiais, mas é mais comumente usado para definir a opacidade de uma cor. Discutiremos essa e outras representações em aulas futuras.
2.6. Onde estamos e para onde vamos?#
Compreender o processo de formação de imagens usando uma câmera virtual é muito importante para entender os próximos tópicos que serão apresentados no curso. Na próxima aula, vamos apresentar mais detalhes sobre sistemas gráficos e a arquitetura pipeline dominante nas unidades de processamento gráfico modernas. Ao final do processo, nossos programas gráficos vão produzir imagens raster.
2.7. Exercícios#
Uma forma conhecida como
ray-tracing(tracejamento de raios) para gerar imagens é seguir cada raio que atinge a imagem até encontrar um objeto e, dependendo das propriedades do material nesse ponto de encontro, verificar se o ponto é iluminado por alguma fonte de luz para determinar a sua cor. Quais as vantagens e desvantagens de usarray-tracingem relação ao uso de câmeras virtuais usadas pela maioria dos pipelines gráficos?Considere um sensor de resolução \(640\times480\) pixels. O sensor ocupa toda a face posterior de uma câmera pinhole. O centro de projeção da câmera está no centro da face oposta. Considere que o comprimento focal é 320 pixels. Nesse caso, qual o FoV vertical? E o FoV horizontal?
Discuta em que condições a seguinte afirmação pode ser considerada verdadeira ou falsa: A câmera pinhole é um bom modelo para o olho humano.