5.4. A Busca Binária¶
É possível obter uma grande vantagem do fato de uma lista estar ordenada se formos espertos o bastante com as nossas comparações. Na busca sequencial, quando iniciamos a comparação a partir do primeiro item, há no máximo mais \(n-1\) elementos a serem buscados se o primeiro item não era o que estávamos procurando. Em vez de procurar o item sequencialmente, uma busca binária irá começar examinando o item do meio. Se esse elemento é o que estamos buscando, a procura terminou. Se não for o item correto, podemos utilizar o fato da lista estar ordenada para eliminar metade dela. Se o item que estamos procurando for maior que o elemento do meio, sabemos que a metade inferior (contando com o item do meio) não precisa mais ser levada em consideração. O item, se estiver na lista, necessariamente está na metade superior.
Podemos então repetir o processo com a parte superior. Começamos pelo item do meio e o comparamos com o que estamos buscando. Novamente, ou o item do meio é igual ao que buscamos, ou divimos a lista no meio, eliminando então outra parte considerável do nosso espaço de busca. A Figura 3 mostra como esse algoritmo consegue encontrar rapidamente o valor 54. A função completa é exibida em CodeLens 3.
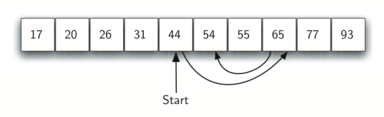
Figura 3: Busca Binária em Uma Lista Ordenada de Inteiros¶
Busca Binária em uma Lista Ordenada (search3)
Antes de irmos para a análise, note que esse algoritmo é um ótimo exemplo da estratégia de dividir para conquistar, isto é, nós dividimos o problema em partes menores, resolvemos as menores partes de algum modo e então remontamos tudo para chegar ao resultado. Quando nós realizamos uma busca binária de uma lista, primeiro checamos o item do meio. Se o item que estamos procurando é menor que o item intermediário, nós simplesmente fazer uma busca binária na metade esquerda da lista original. Do mesmo modo, se o item for maior, nós realizamos uma binária na metade direita. De qualquer forma, trata-se de uma chamada recursiva da função de busca binária passando uma lista menor como parâmetro. CodeLens 4 mostra essa versão recursiva.
Uma Busca Binária--Versão Recursiva (search4)
5.4.1. Análise da Busca Binária¶
Para analisar o algoritmo de busca binária, precisamos ter em mente que cada comparação elimina cerca de metade dos itens restantes a serem considerados. Qual é o número máximo de comparações que esse algoritmo irá requerer para checar a lista inteira? Se começarmos com n itens, em torno de \(\frac{n}{2}\) itens sobrarão após a primeira comparação. Depois da segunda comparação, haverá cerca de \(\frac{n}{4}\), depois \(\frac{n}{8}\), \(\frac{n}{16}\) e assim por diante. Mas quantas vezes podemos dividir essa lista? A Tabela 3 nos ajuda a responder essa pergunta.
Comparações |
Número aproximado de itens restantes |
|---|---|
1 |
\(\frac {n}{2}\) |
2 |
\(\frac {n}{4}\) |
3 |
\(\frac {n}{8}\) |
… |
|
i |
\(\frac {n}{2^i}\) |
Quando nós quebramos a lista um número suficiente de vezes, acabamos ficando com uma lista composta por um único item. Logo, ou esse item é aquele que estamos buscando ou não é. De qualquer forma, o processo termina. O número necessário de comparações para chegar a esse ponto é i, onde \(\frac {n}{2^i} = 1\). Isolando i, ficamos com \(i=\log n\). Assim, o número máximo de comparações é o logaritmo do número de itens na lista. Portanto, a busca binária é \(O(\log n)\).
Uma questão adicional de análise ainda precisa ser tratada. Na solução recursiva mostrada acima, a chamada recursiva
binarySearch(alist[:midpoint],item)
usa o operador de fatiamento para criar a metade esquerda da lista que é passada para a próxima chamada (e, da mesma maneira, para a metade direita). A análise que fizemos acima pressupõe que o operador de fatiamento tem tempo constante. Contudo, nós sabemos que na verdade o operador de fatiamento em Python é O(k). Isso significa que a busca binária usando esse operador não irá ter um desempenho estritamente logarítmico. Felizmente isso pode ser remediado passando a lista junto com os índices de começo e fim. Os índices podem ser calculados como fizemos em Listing 3 <lst_binarysearchpy>`. Deixamos essa implementação como um exercício.
Embora uma busca binária seja geralmente melhor que uma sequencial, é importante notar que para valores pequenos de n, o custo adicional de ordenar a lista provavelmente não vale a pena. Na verdade, sempre deveríamos considerar o custo-benefício do trabalho adicional de ordenação para obter benefícios na busca. Se nós podemos ordenar uma vez e então fazer inúmeras buscas, o custo da ordenação não é tão significativo. Entretanto, para listas muito grandes, a ordenação, mesmo que feita uma única vez, pode ser tão cara que simplesmente fazer uma busca sequencial desde o começo pode se mostrar uma escolha melhor.
Auto-avaliação
- 11, 5, 6, 8
- Parece que você errou por um. Lembre-se de que a primeira posição tem índice 0.
- 12, 6, 11, 8
- A busca binária começa pelo meio e divide a lista um turno por vez.
- 3, 5, 6, 8
- A busca binária não começa pelo início e busca sequencialmente, ela começa pelo meio e divide a lista após cada comparação.
- 18, 12, 6, 8
- Parece que você está começando pelo fim e dividindo a lista um turno por vez.
Q-1: Suponha que você tenha a lista ordenada [3, 5, 6, 8, 11, 12, 14, 15, 17, 18] e que você esteja usando o algoritmo recursivo da busca binária. Qual grupo de números mostra corretamente a sequência de comparações usadas para encontrar a chave 8?
- 11, 14, 17
- Parece que você errou por um. Lembre-se de que a primeira posição tem índice 0.
- 18, 17, 15
- Lembre-se: a busca binária começa pelo meio e depois divide a lista.
- 14, 17, 15
- Parece que você errou por um. Cuidado quando estiver calculando o ponto central usando aritmética de inteiros.
- 12, 17, 15
- A busca binária começa pelo elemento do meio e divide a lista a cada turno. Ela termina quando a lista está vazia.
Q-2: Suponha que você tenha a lista ordenada [3, 5, 6, 8, 11, 12, 14, 15, 17, 18] e que você esteja usando o algoritmo recursivo da busca binária. Qual grupo de números mostra corretamente a sequência de comparações usadas para encontrar a chave 16?