5.3. A Busca Sequencial¶
Quando itens de dados são armazenados numa coleção tal qual uma lista, nós dizemos que eles têm uma relação linear ou sequencial. Cada item de dado é armazenado numa posição relativa aos demais. Em listas do Python, essas posições relativas são os índices dos itens individuais. Como esses índices estão ordenados, é possível que nós visitemos os itens sequencialmente. Esse processo dá origem à nossa primeira técnica de busca, a busca sequencial.
Figura 1 mostra como essa busca funciona. Começando pelo primeiro item da lista, nós simplesmente andamos de item a item, obedecendo à disposição sequencial até que encontremos o que nós estamos procurando ou que não haja mais itens a serem buscados. Quando não há mais itens, então chegamos à conclusão de que o item buscado não estava presente.

Figura 1: Busca sequencial de uma lista de inteiros¶
A implementação em Python para esse algoritmo é mostrada em
CodeLens 1. A função precisa da lista e do item
que estamos procurando e retorna um valor booleano para indicar se está
presente ou não. A variável booleana found é inicializada com False e
muda de valor para True caso o item seja encontrado na lista.
Busca sequencial em uma lista não ordenada (search1)
5.3.1. Análise da Busca Sequencial¶
Para analisar algoritmos de busca, precisamos chegar a um consenso sobre a unidade básica de computação. Lembre-se de que este é o típico passo a ser dado repetidas vezes para que o problema seja solucionado. Na busca, faz sentido contar o número realizado de comparações. Cada comparação pode ou não encontrar o item que estamos procurando. Além disso, fazemos outra suposição. A lista de itens não está ordenada de maneira alguma. Os itens foram colocados aleatoriamente na lista. Em outras palavras, a probabilidade de que o item que estamos procurando esteja numa posição em particular é exatamente a mesma para cada posição da lista.
Se o elemento não está na lista, a única maneira de ter certeza é comparando-o com cada outro item da lista. Se exsitem \(n\) itens, então a busca sequencial requer \(n\) comparações para descobrir que tal elemento não está lá. Caso o item esteja na lista, a análise já não é tão simples. Existem, nesse caso, três diferentes cenários que podem ocorrer. No melhor caso, iremos encontrar o item na primeira posição que procurarmos, isto é, no começo da lista. Consequentemente, só precisaremos de uma comparação. No pior caso, só conseguiremos encontrar o item na última posição, ou seja, realizando a n-ésima comparação.
E quanto ao caso médio? Na média, nós iremos encontrar o item mais ou menos na metade da lista, isto é, faremos \(\frac{n}{2}\) comparações com outros elementos. Lembre-se, contudo, de que conforme n se torna grande, os coeficientes, independente de quais sejam, tornam-se insignificantes na nossa aproximação, então a complexidade da busca sequencial é \(O(n)\). A Tabela 1 resume esses resultados.
Caso |
Melhor Caso |
Pior Caso |
Caso Médio |
|---|---|---|---|
item presente |
\(1\) |
\(n\) |
\(\frac{n}{2}\) |
item não presente |
\(n\) |
\(n\) |
\(n\) |
Nós presumimos anteriormente que os itens em nossa coleção foram posicionados aleatoriamente de modo que não houvesse ordem relativa entre eles. O que aconteceria à busca sequencial se os itens estivessem ordenados de alguma forma? Conseguiríamos obter alguma eficiência na nossa técnica de busca?
Suponha que a lista de itens tenha sido construída de tal forma que eles tenham sido posicionados em ordem crescente, do menor para o maior. Se o item que estamos buscando estiver na lista, a probabilidade de ele estar em uma das n posições continua a mesma. Nós ainda temos que fazer o mesmo número de comparações para encontrá-lo. Contudo, se o item não estiver presente, há uma pequena vantagem. A Figura 2 exemplifica isso conforme o algoritmo procura pelo item 50. Observe que os elementos continuam sendo comparados sequencialmente até o 54. Mas nesse ponto, porém, temos uma informação extra. Além de o item 54 não ser aquele que estamos procurando, não é possível que o nosso item esteja em alguma posição superior a 54, pois a lista está ordenada. Nesse caso, o algoritmo não precisa continuar procurando no restante da lista para informar que o item não foi encontrado. Ele pode parar imediatamente. O CodeLens 2 mostra essa variação da função de busca sequencial.
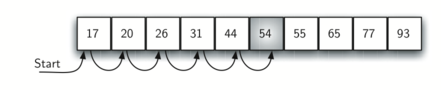
Figura 2: Busca Sequencial em uma Lista Ordenada de Inteiros¶
Busca Sequencial em uma Lista Ordenada (search2)
A Tabela 2 resume esses resultados. Observe que no melhor caso nós temos condições de saber se o item não está na lista olhando apenas para um elemento. Na média, iremos descobrir isso depois de procurar por apenas \(\frac {n}{2}\) itens. No entanto, essa técnica é ainda \(O(n)\). Em suma, a busca sequencial é melhorada quando sabemos que a lista está ordenada somente no caso em que não encontramos o item.
Auto-avaliação
- 5
- Cinco comparações iriam devolver o segundo 18 na lista.
- 10
- Você não precisa buscar na lista toda, apenas até encontrar a chave que você está procurando.
- 4
- Não, lembre-se de que numa busca sequencial você inicia pelo começo e checa cada chave até encontrar o que você está procurando ou a lista terminar.
- 2
- Neste caso, apenas 2 comparações foram necessárias para encontrar a chave.
Q-1: Suponha que você esteja fazendo uma busca sequencial na lista [15, 18, 2, 19, 18, 0, 8, 14, 19, 14]. Quantas comparações você precisaria fazer para encontrar a chave 18?
- 10
- Você não precisa buscar na lista inteira. Como ela está ordenada, você pode parar de procurar quando você fizer uma comparação com um valor maior do que a chave.
- 5
- Como 11 é menor do que 13, você precisa continuar procurando.
- 7
- Como 14 é maior do que 13, você pode parar.
- 6
- Como 12 é menor do que 13, você precisa continuar procurando.
Q-2: Suponha que você esteja fazendo uma busca sequencial na lista ordenada [3, 5, 6, 8, 11, 12, 14, 15, 17, 18]. Quantas comparações você precisaria fazer para encontrar a chave 13?