Algoritmos no divã#
No nosso estudo continuaremos a ter dicionários e suas aplicações como pano de fundo para explorarmos o universo dos algoritmos. Estruturas de dados, como dicionários, são diariamente aplicadas para o armazenamento de informação que posteriormente são consultadas. É de interesse que as consultas sejam respondidas rapidamente. Cada mecanismo de armazenamento e busca tem suas vantagens e desvantagem. Dependendo da aplicação, os dados são mantidos respeitando alguma ordem e essa ordenação pode ser explorada durante as consultas.
Nesse capítulo nos aprofundaremos em métodos para estimativa dos recursos computacionais utilizados por funções e algoritmos. Traremos, por assim dizer, os algoritmos para o divã para analisá-los com mais cuidado. Esse tópico e comumente chamado de análise de algoritmos.
Destino#
Entraremos agora nos domínios da análise de algoritmos. 🤓 Praticaremos a análise experimental de algoritmos e as técnicas cotidianamente utilizadas para estimar o tempo gasto e espaço consumido por programas, especialmente o tempo gasto. Essas análises nos farão compreender os pontos fortes, fracos e os limites dos nossos programas.
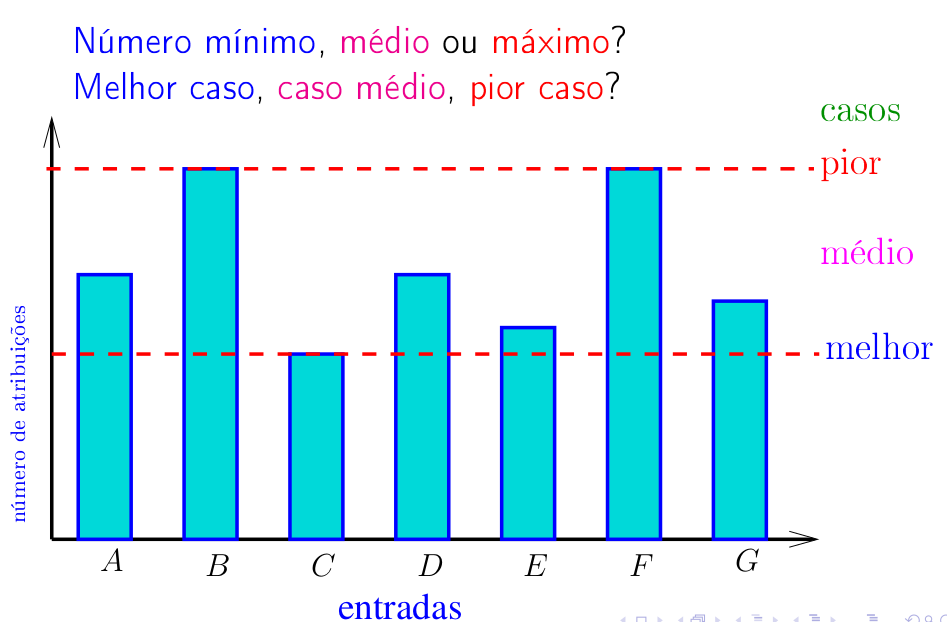
É comum examinarmos as situações que em que um algoritmo ou função requer mais tempo ⏲️ ou espaço de armazenamento ou de memória 📝. Chamamos essas situações de pior caso 😔. Quando investigamos a situação em que um algoritmo ou função requer poucos recursos, seja em termos de tempo ou espaço consumido, estaremos falando do desempenho de melhor caso 😄. Muitas vezes também é de interesse saber o desempenho médio do algoritmo ou função que podem estar mais próximos da prática do dia a dia. Essa é a chamada análise de caso médio 😕.
Do ponto de vista de ideias, é importante compreender que decisões de projeto frequentemente tem seus pontos positivos e negativos. Tentem praticar o senso crítico considerando as vantagens e desvantagens da busca sequencial, da busca em listas ordenadas e da busca binária. Revisitaremos os algoritmos o problema do máximo divisor comum vistos na seção Máximo divisor comum e Euclides. Procurem habituar-se a linguagem usada por manuais para expressar o consumo de tempo de funções e métodos através da notação assintótica, como na wiki TimeComplexity. Busquem nos experimentos evidências para comprovar ou contestar as nossas expectativas, as nossas estimativas analíticas, teóricas. Todos os algoritmos que estudaremos, entre eles a ordenação por inserção, serão um imenso laboratório de ideias.
Buscas em listas#
Para aquecer os nossos motores …
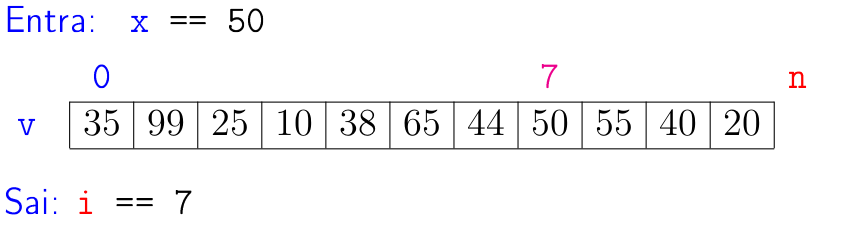
Problema (busca): Dado um objeto
xe uma listav[0:n], encontrar um índiceital quev[i] = x.
Nos exemplos a seguir, uma lista é formada por objetos int, no entanto poderiam ser objetos de qualquer classe.
O importante é que todos os elementos de v sejam comparáveis entre si.
Uma maneira de resolvermos esse problema é através de uma busca sequencial: percorremos a lista examinando seus elementos um a um, do início até o fim ⏩ ou do fim até o início 🔙.
def sequencial(v, x):
''' (list, obj) -> int or None
RECEBE uma lista v e um objeto x.
RETORNA o menor índice i tal que v[i] == x.
Se o x não está na lista a função retorna None.
'''
0 n = len(v)
1 for i in range(n): #1#
2 if x == v[i]: return i
3 return None
A numeração das linhas não faz parte dos código e só está ai para efeito de referência.
Passamos agora a verificação de que a função sequencial() está correta.
Estar correta significa que a função funciona, faz o que promete.
A correção de algoritmos iterativos é comumente baseada na verificação da validade de invariantes.
Estes invariantes são afirmações ou relações envolvendo os objetos mantidos pela função.
Em #1# no início de cada iteração vale que val != x para todo val em v[0:i].
No início da última iteração vale que ou x == v[i] e a função retorna o índice i,
ou que percorremos todos os elementos de v e a função retorna None pois x não está na lista.
Logo, a função retorna uma resposta correta.
🤔 Relações invariantes, com a que apresentada acima envonvendo os objetos val, x e v[0:i], além de serem uma ferramente
útil para demonstrarmos a correção de algoritmos iterativos, elas nos ajudam a compreender o funcionamento do algoritmo.
De certa forma, no fundo no fundo, as relações invariantes espelham a maneira que entendemos e concebemos o algoritmo.
Bem , passemos a tratar do consumo de tempo ⏲️ de sequencial().
Para estimarmos o consumo de tempo da função suporemos que o consumo de tempo de cada execução de uma linha é constante, digamos, 1 unidade de tempo.
A tabela abaixo resumo o consumo de tempo máximo 🕙 de cada linha.
Essa análise é de pior caso pois estamos estimando o maior número possível de linhas que podem ser executadas.
Conclusão. O consumo de tempo da função
busca_sequecial()é no pior caso proporcional ao número de elementosnda listav.
No melhor caso, quando a função trabalha pouco, x é um elemento logo no início da lista e o tempo gasto passa a independer do número n de elementos.
Nesse caso dizemos que o consumo de tempo é constante já que independe do volume de dados.
Realizando experimentos vemos que, à medida que o tamanho da lista dada dobra, o consumo de tempo aproximadamente dobra. Esse é o comportamento esperado por uma função que possui consumo de tempo linearmente proporcional a \(\mathtt{n}\). Os tempos na tabela abaixo e os testes foram feitos com buscas bem-sucedidas, onde o elemento procurado estava na lista. Esse elemento foi sorteado dentre os elementos da lista.
Testes apenas para buscas BEM-SUCEDIDAS: x está em v
n busca_sequencial
1024 0.00
2048 0.00
4096 0.00
8192 0.00
16384 0.00
32768 0.00
65536 0.00
131072 0.01
262144 0.01
524288 0.03
1048576 0.05
2097152 0.10
4194304 0.20
8388608 0.40
16777216 0.83
33554432 1.61
Buscas em listas ordenadas#
Dizemos que uma lista \(\mathtt{v[0:n]}\) é crescente se
Passemos a pensar sobre o seguinte problema de busca.
Problema (busca em lista ordenada): Dado um objeto
xe um lista crescentev[0:n]encontrar um índiceital quev[i] = x.
Nos exemplos a seguir, uma lista é formada de objetos int, no entanto poderiam ser objetos de qualquer classe.
O importante é que os elementos de v sejam comparáveis entre si (ou seja, dois a dois)
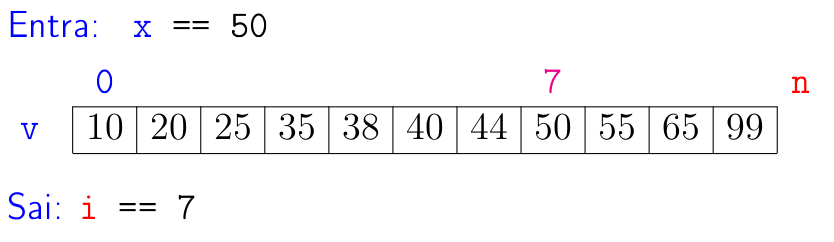

Podemos adaptar a busca sequencial para tirar proveito da ordenação dos elementos da lista. Na função a seguir, os números indicando a linha não fazem parte do código e servem de rótulos para que possamos referi-las.
def buscaA(v, x):
''' (list, obj) -> int or None
RECEBE uma lista v e um objeto x.
RETORNA o menor índice i tal que v[i] == x.
Se o x não está na lista a função retorna None.
PRÉ-CONDIÇÃO: supõe que a lista é crescente.
'''
0 n = len(v)
1 i = 0
2 while i < n and x > v[i]: #1#
3 i += 1
4 if i < n and v[i] == x:
5 return i
6 return None
Abaixo está uma simulação da função busca_sequencial()
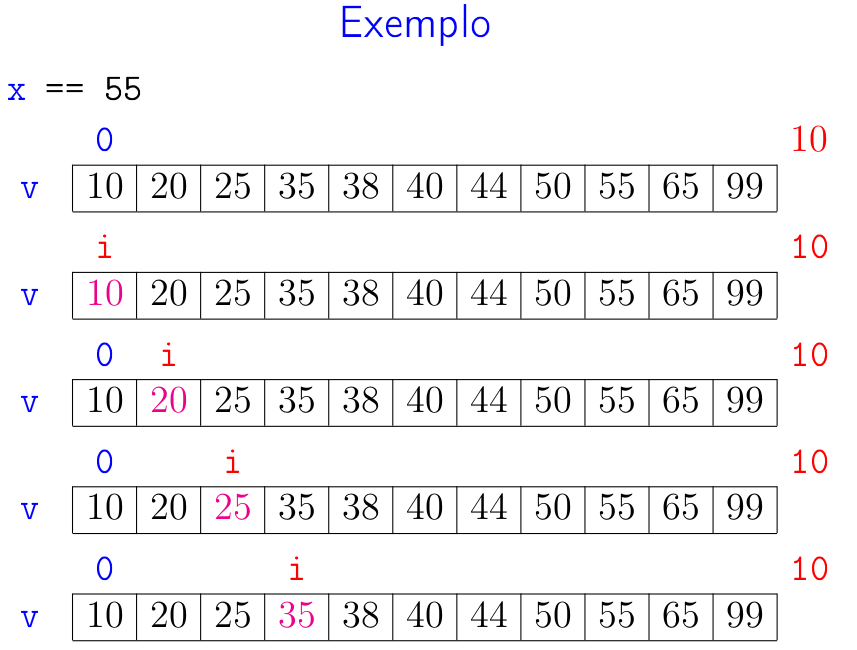
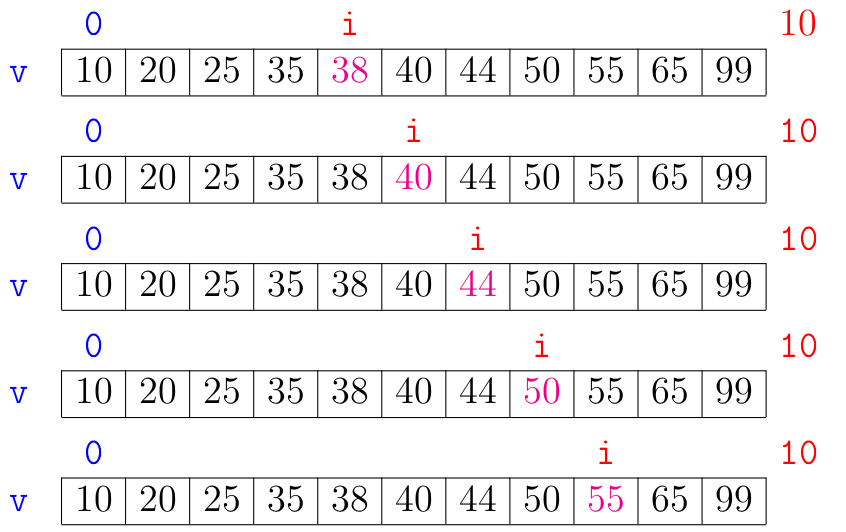
O funcionamento da função se baseia no fato de que, em #1# vale que v[i-1] < x.
Como a lista é crescente, então val < x para todo val in v[0:i].
No início da última iteração temos que ou i >= n ou v[i] >= x.
Assim, na linha 6, se a função retorna um índice i, então v[i] == x.
Por outro, se i == n ou v[i] > x, a função acertadamente retorna None na linha 7 e já que
nesse ponto do código temos provas cabais de que x não tem a menor chance de estar na lista.
Para analisarmos o consumo de tempo da função buscaA() suporemos que
a execução de cada linha consome uma quantidade de tempo limitada por uma constante, como 1 microsegundo, \(1 \mu\) s.
Equivalentemente, podemos supor que a execução de cada linha consome 1 unidade de tempo.
Dessa forma o tempo total é mostrado na tabela a seguir.
Na tabela, não se preocupe com a parte do \(\mathtt{= \textup{O}(n)}\), que ficará mais clara mais adiante.
Conclusão. O consumo de tempo da função
buscaA()é no pior caso proporcional ao número de elementosnda listav.
Examinando o código da função buscaA() percebemos que para buscas
malsucedidas, quando o objeto x não está na lista,
buscaA() pode consumir mais tempo que uma busca sequencial
ordinária. Considere a situação em que x não está na lista v e
x é maior que todo elemento em v. Nesse cenário buscaA()
faz o mesmo número de passos que a busca sequencial e, em cada passo,
faz uma comparação a mais.
Realizando alguns experimentos de buscas bem-sucedidas, ou seja, o
objeto x sendo procurado estava na lista, obtivemos a seguinte
tabela de tempos. Para valores suficientemente grandes é possível
ver que, quando n dobra, o tempo consumido também aproximadamente dobra.
Esse é um sintoma típico de funções que tem seu consumo de tempo
proporcional a n: se n dobra então o consumo de tempo aproximadamente dobra.
A tabela a seguir mostra resultados de experimentos feitos com a função buscaA().
Testes apenas para buscas BEM-SUCEDIDAS: x está em v
n buscaA
1024 0.00
2048 0.00
4096 0.00
8192 0.00
16384 0.00
32768 0.00
65536 0.00
131072 0.01
262144 0.01
524288 0.03
1048576 0.05
2097152 0.10
4194304 0.20
8388608 0.41
16777216 0.83
33554432 1.66
Busca binária#
Quando fazemos busca em listas ordenadas o método de escolha é a busca binária.
Essa busca se apoia em um princípio bem simples.
Se v[e:d] é uma lista crescente
e v[i] < x para algum i em range(e,d), então não precisamos nos preocupar com x em v[i+1:d].
De maneira semelhante, v[i] > x, então não precisamos nos preocupar com x em v[e:i].
def busca_bin(v, x):
''' (list, obj) -> int ou None
RECEBE uma lista v e um objeto x.
RETORNA um índice i tal que v[i] == x.
Se o x não está na lista a função retorna None.
PRÉ-CONDIÇÃO: supõe que a lista é crescente.
'''
0 n = len(v)
1 e = 0
2 d = n
3 while e < d: #1#
4 m = (e + d) // 2
5 if v[m] == x: return m
6 if v[m] < x: e = m + 1
7 else: d = m
8 return None
A seguir está uma simulação que mostra a busca binária em ação.
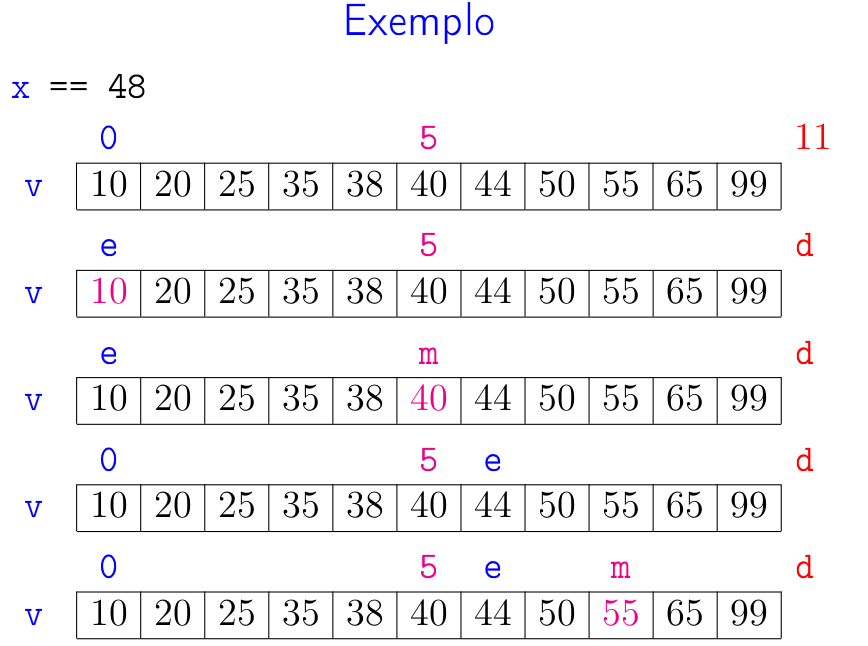
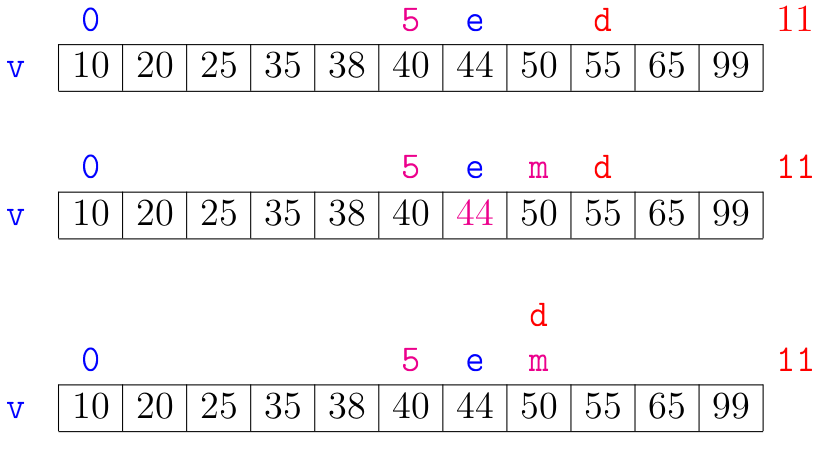
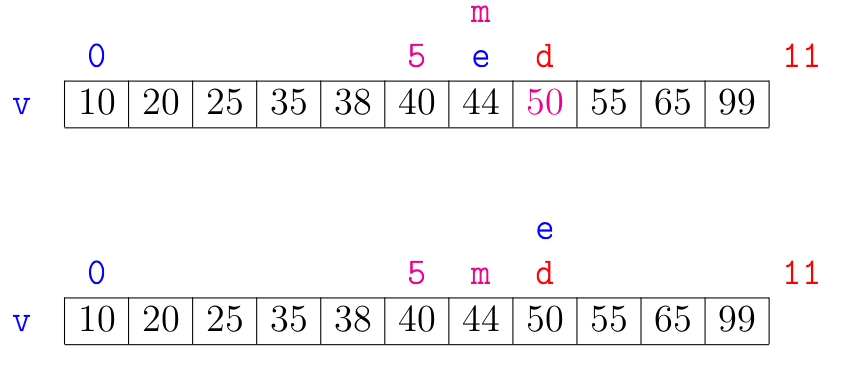
A correção da função busca_bin() se apoia na seguinte relação invariante chave: em #1# vale que:
val < xpara todo valorvalemv[0:e]ex < valpara todo valorvalemv[d:n].
Essa relação vale na primeira iteração se concordarmos em interpretar val na lista vazia v[0:0] como sendo \(-\infty\) e
val na lista vazia v[n:n] como sendo \(+\infty\).
Se x não está em v, então no início da última iteração das linhas 3 a 7 teremos que e == d.
Portanto, da relação invariante, x será um valor maior que todo elemento em v[0:e] e menor que todo elemento em v[e:n].
Isso mostra que x não está em v e a função acertadamente retorna None na linha 8.
No que diz respeito ao consumo de tempo da função busca_bin(), vemos que ele é proporcional ao
número \(\mathtt{k}\) de iterações das linhas 3 a 7.
No início da primeira iteração tem-se que d-e = n.
Sejam
os valores das variáveis e e d no início de cada uma das iterações.
No pior caso, quando a função faz mais trabalho, x não está em v e, portanto, a busca é mal sucedida.
Assim, \(\mathtt{d_{k-1} - e_{k-1} > 0}\) e \(\mathtt{d_{k} - e_{k} \leq 0}\).
Estimaremos o valor de \(\mathtt{k}\) em função de \(\mathtt{d-e}\).
Note que \(\mathtt{d_{i+1} - e_{i+1} \leq (d_{i}-e_{i}) / 2}\) para \(\mathtt{i=1,2,\ldots,k-1}\).
Desta forma temos que
Observe que depois de cada iteração o valor de \(\mathtt{d-e}\) é reduzido pela metade. Seja \(\mathtt{t}\) o número inteiro tal que \(\mathtt{2^{t} \leq n < 2^{t+1}}\). Da primeira desigualdade temos que \(\mathtt{t \leq \lg n}\), em que \(\mathtt{\lg n}\) é o logaritmo de \(\mathtt{n}\) na base 2. Da desigualdade estrita, concluímos que
Assim, em particular temos que
ou, em outras palavras
Portanto , o número \(\mathtt{k}\) de iterações é não superior a
Chegamos portanto ao seguinte desfecho.
Conclusão. O consumo de tempo da função
busca_bin()é, no pior caso, proporcional a \(\mathtt{\lg n}\).
A tabela a seguir mostra o possível número de iterações no pior caso das funções buscaA(), que faz uma busca sequencial, e da busca_bin(), que realiza uma busca binária.
Admiremos agora alguns resultados experimentais sobre listas de diferente tamanhos comparando os
consumos de tempo de buscaA() e de busca_bin().
Testes apenas para buscas BEM-SUCEDIDAS: x está em v
n buscaA busca_bin
1024 0.00 0.00
2048 0.00 0.00
4096 0.00 0.00
8192 0.00 0.00
16384 0.00 0.00
32768 0.00 0.00
65536 0.00 0.00
131072 0.01 0.00
262144 0.01 0.00
524288 0.02 0.00
1048576 0.01 0.00
2097152 0.10 0.00
4194304 0.21 0.00
8388608 0.47 0.00
16777216 0.91 0.00
33554432 2.69 0.00
67108864 4.85 0.00
Como podemos observar o tempo gasto pela função busca_bin() é menor que o nosso padrão de medida com duas casas decimais e por isso todos são mostrado como \(\mathtt{0.00}\).
Apesar da função busca_bin() não ser recursiva, a busca binária é visceralmente recursiva.
A seguir está uma implementação recursiva da busca binária. Nesta versão busca_bin() é uma envoltória da função recursiva busca_binariaR() que faz todo o serviço.
Essa envoltória faz o mesmo papel que vimos sendo desempenhado pelas funções fibonacciRM() e binomialRM(), de esconder alguns parâmetros usados na recursão.
def busca_bin(v, x):
''' (list, obj) -> int ou None
RECEBE uma lista v e um objeto x.
RETORNA um índice i tal que v[i] == x.
Se o x não está na lista a função retorna None.
PRÉ-CONDIÇÃO: supõe que a lista é crescente.
'''
n = len(v)
return busca_binariaR(v, x, 0, n)
def busca_binariaR(v, x, e, d):
''' (lst, obj, e, d) -> int ou None
RECEBE uma lista crescente v[e:d] e um objeto x.
Retorna um índice m , e <= m < d tal que v[m] == x .
Se tal m não existe, retorna None.
PRÉ-CONDIÇÃO: supõe que v[e:d] é crescente.
'''
if d <= e: return None
m = (e + d) // 2
if v[m] == x: return m
if v[m] < x: return busca_binariaR(v, x, m+1, d)
return busca_binariaR(v, x, e, m)
Ordenação por inserção#
Dizemos que uma lista \(\mathtt{v[0:n]}\) é crescente se
O problema que trataremos aqui será o de ordenar uma lista de elementos.
Problema (ordenação): Rearranjar os elementos de uma lista
v[0:n]de modo que ela fique crescente.
Nos exemplos as listas são de objetos int, mas elas poderiam ser de str ou de quaisquer objetos que possam ser comparados com operadores relacionais como <, <=, > ou >=.
O algoritmo que veremos aqui é dinâmico no sentido que ele é ideal para manter uma lista ordenada a medida que novos elemento são inseridos. A ideia chave do algoritmo é supor que temos uma lista v que já é crescente e desejamos inserir um novo elemento na lista mantendo-a crescente.
O algoritmo é iterativo.
No início de cada iteração um prefixo v[0:i] da lista v é crescente.
A missão da iteração é rearranjar os elemento de v[0:i+1] para que esse prefixo seja crescente.
O elemento da lista que terá um papel fundamental na iteração é x = v[i].
Esse valor x é chamado de o pivô da iteração.
Cada iteração será claramente dividida em duas fases:
na primeira fase o algoritmo procura um índice
jemrange(i)tal quev[j] <= xex < v[j+1]na segunda fase o pivô
xé inserido na posiçãov[j+1]
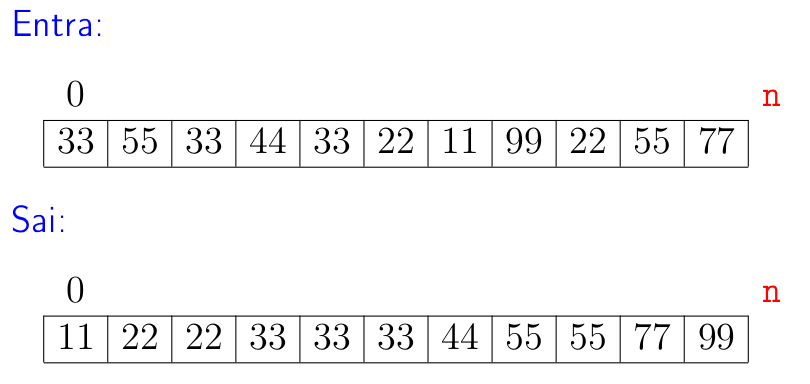
A seguir está a ilustração da simulação de uma iteração.

Na ilustração o prefixo crescente é v[0:6] e o pivô é x = 38 que esta na posição v[6].
Ao final da iteração o prefixo v[0:7] é crescente.
A inserção na segunda fase é o que dá nome ao algoritmo de ordenação por inserção.
Para inserir x na posição v[j+1], vários elementos devem ser deslocados.
Algumas vezes esse deslocamento é feito durante a procura pelo índice j através de uma busca sequencial.
# pivô
x = v[i]
# encontre a posição j através de busca sequencial
j = i - 1
while j >= 0 and v[j] > x:
v[j+1] = v[j]
j -= 1
# insira x na posição que faz v[0:i+1] crescente
v[j+1] = x
Em outras ocasiões o deslocamento é feito depois que o índice j é encontrado.
Essa é a política adotada quando usamos busca binária para encontrar o índice j.
Como v[0:i] é crescente podemos explorar a eficiência da busca binária para encontrar o índice j.
# pivô
x = v[i]
# encontre j através com busca binária
j = busca_binaria(v, x, e=0, d=i)
# desloque os elementos abrindo espaço para x
for k in range(i, j+1, -1):
v[k] = v[k-1]
# insira x na posição que faz v[0:i+1] crescente
v[j+1] = x
A função completa é fornecida a seguir.
def insercao(v):
'''(list) -> None
RECEBE uma lista v.
REARRANJA os elementos de v para que fiquem em ordem
crescente.
NOTA. A função é mutadora.
'''
0 n = len(v)
1 for i in range(1, n): #1#
# pivô
2 x = v[i]
# encontre a posição j através de busca sequencial
3 j = i - 1
4 while j >= 0 and v[j] > x:
5 v[j+1] = v[j]
6 j -= 1
# insira x na posição que faz v[0:i+1] crescente
7 v[j+1] = x
A relação invariante chave dessa função é a de que em #1# vale que v[0:i] é crescente.
Isso vale na primeira iteração já que i = 1 e v[0:1] é uma lista de apenas um elemento e, portanto, evidentemente crescente.
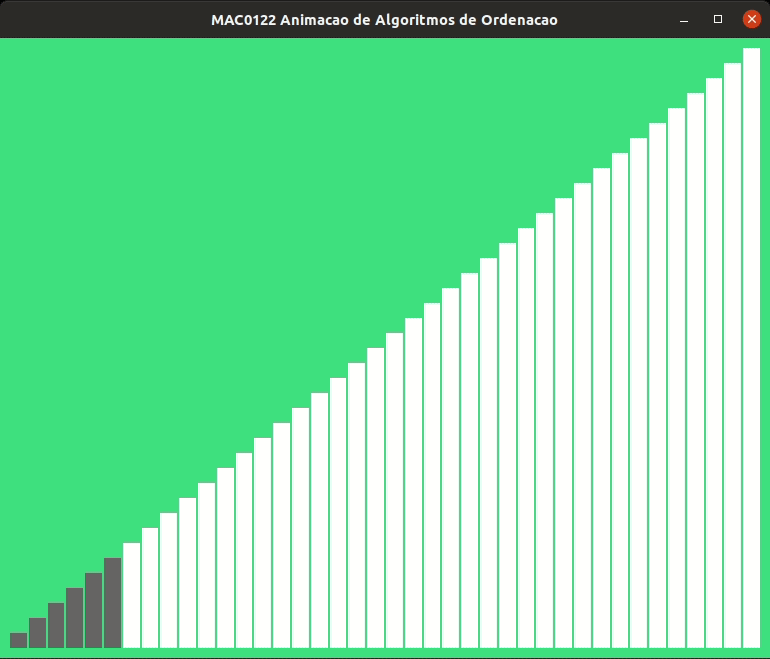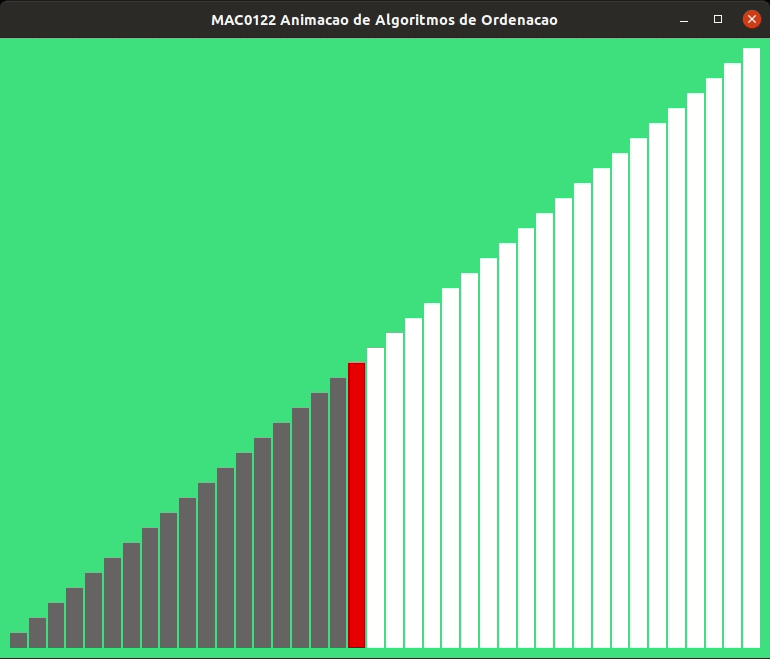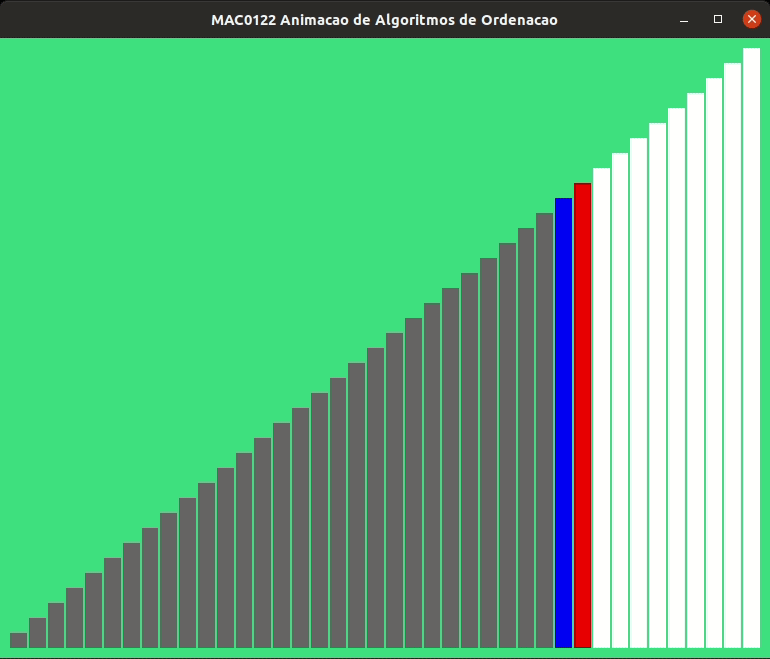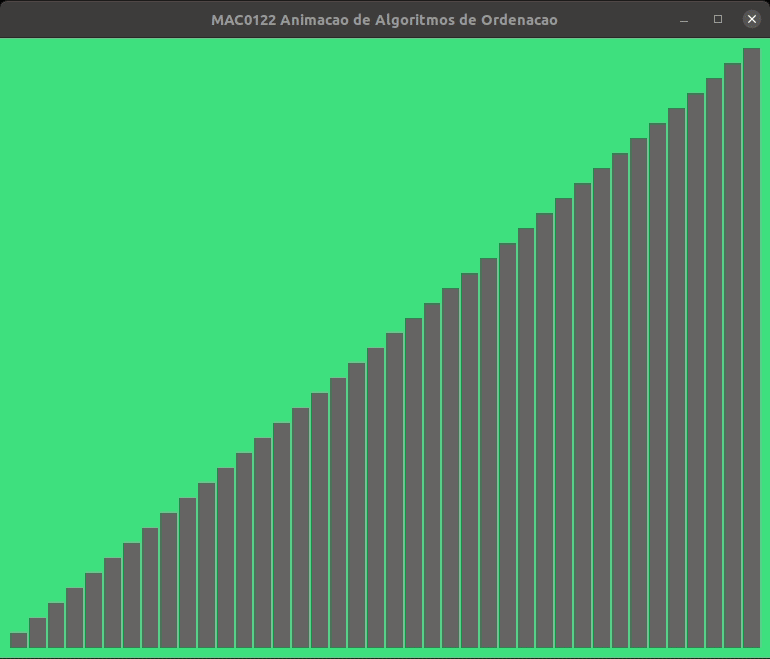
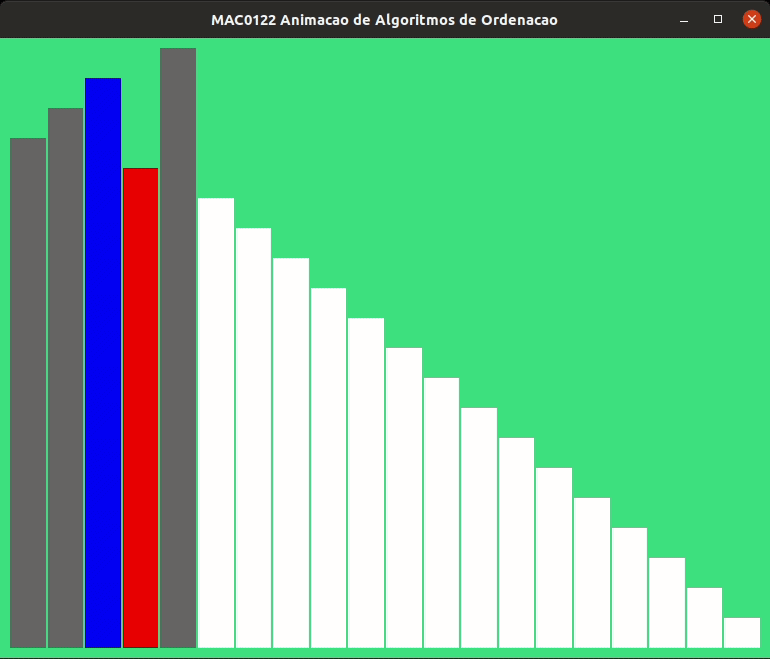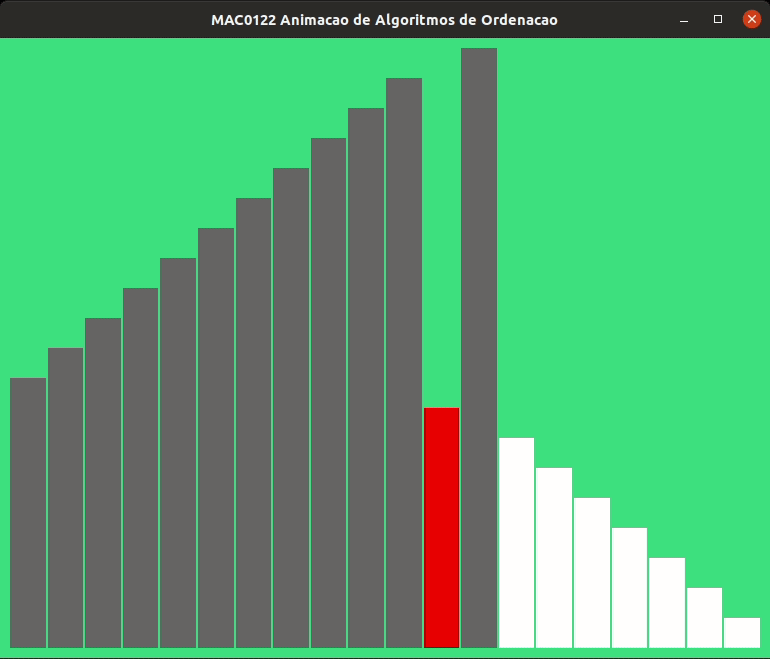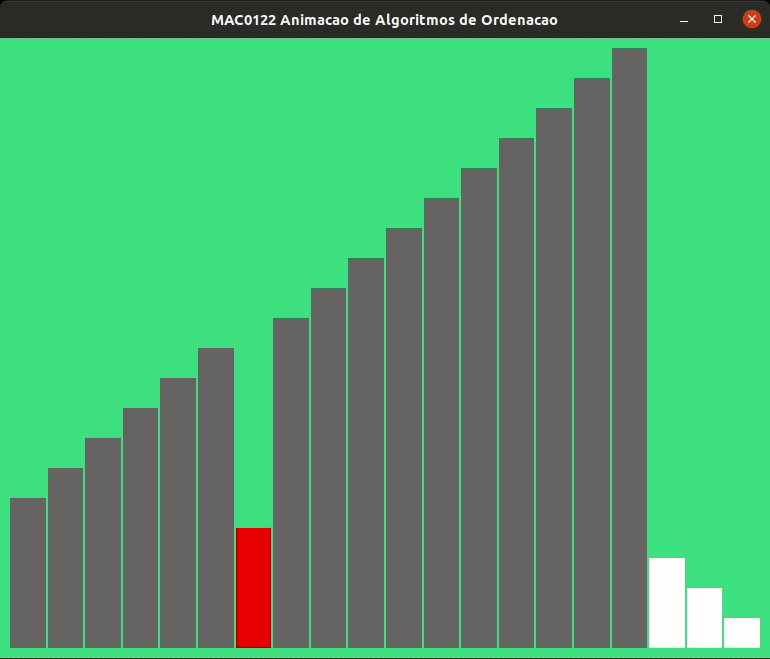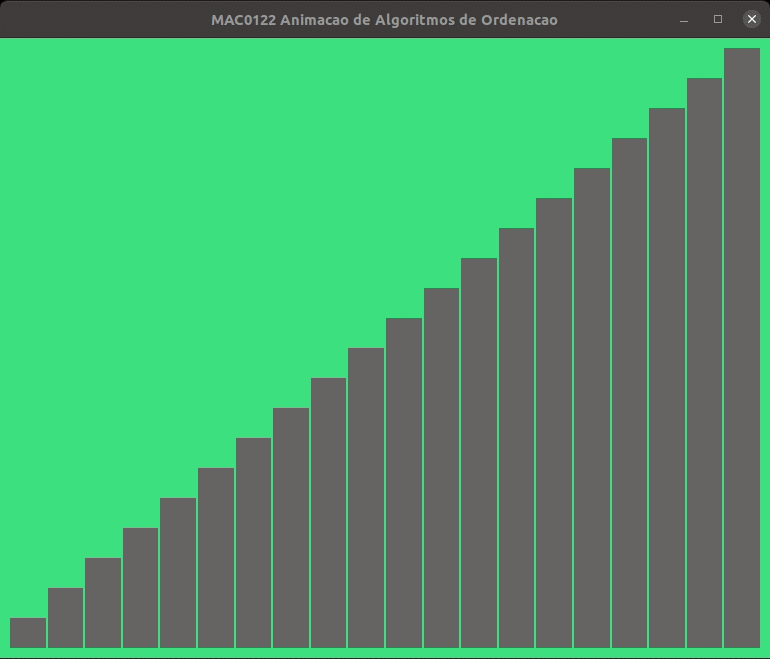
A animação abaixo mostra a ordenação por inserção trabalhando.
As alturas das barras indicam os valores dos elementos de v, quanto maior a barra, maior o valor.
As barras em cinza no início indicam o prefixo v[0:i] crescente.
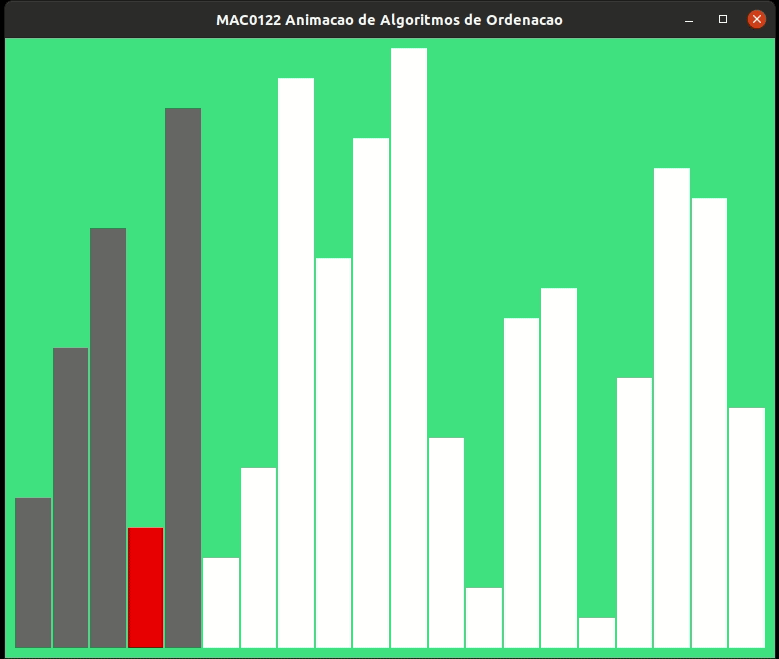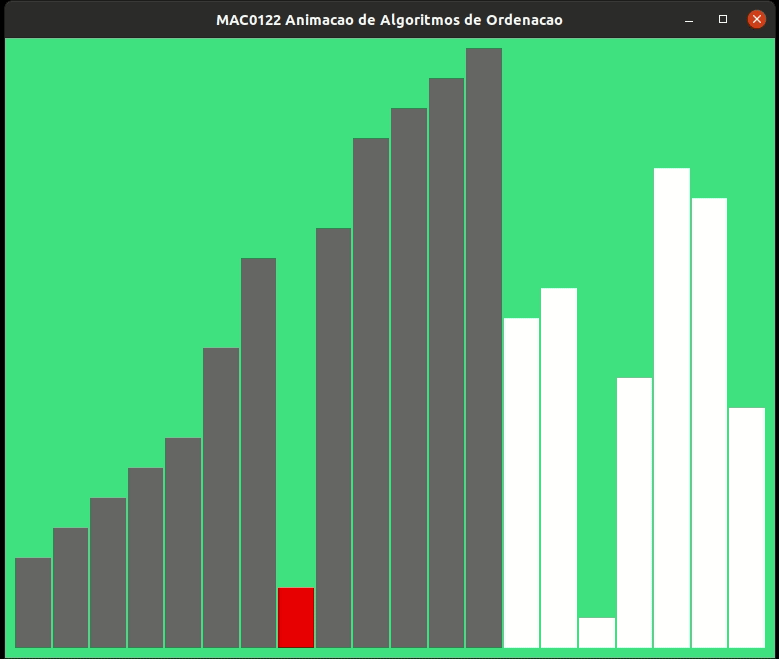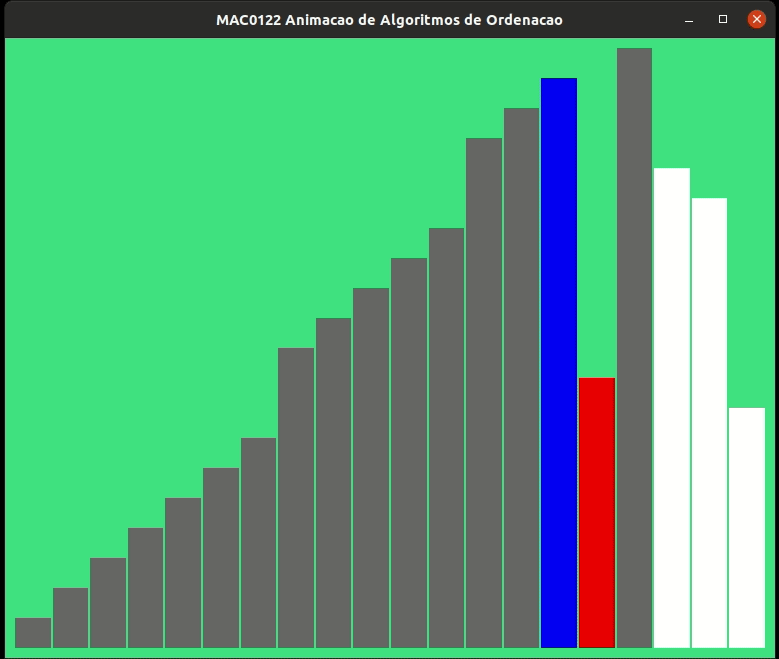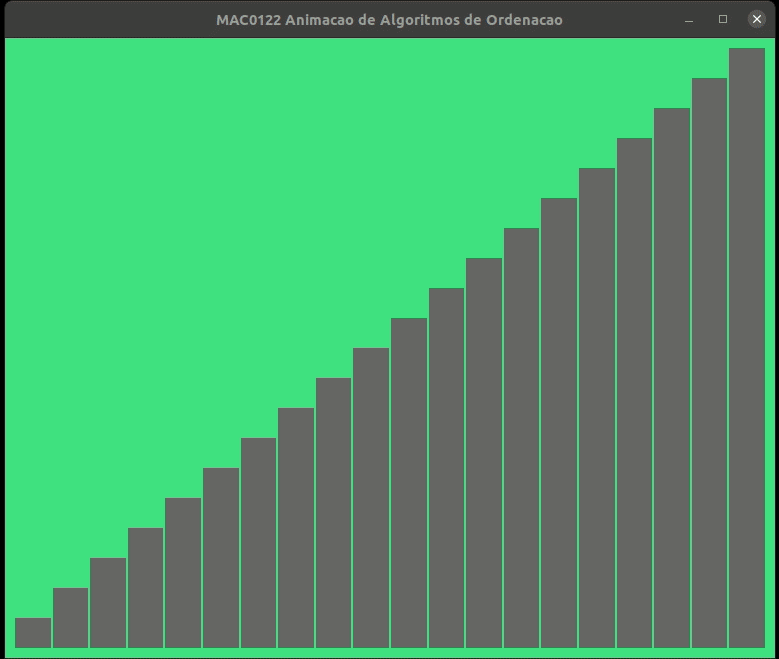
Vamos estimar o consumo de tempo da função insercao() no pior caso. Para isso vamos supor que cada linha consome 1 unidade de tempo para estimar o número de linhas executadas.
O pior caso ocorre quando a função recebe uma lista v decrescente.
Conclusão. O consumo de tempo da função
insercao()é, no pior caso, proporcional a \(\mathtt{n}^2\), em que \(\mathtt{n}\) é o número de elementos na listav.
O melhor caso ocorre quando a função recebe uma lista v já ordenada, em ordem crescente, ou quando os elementos não estão muito distantes de suas posições na lista crescente.
Conclusão. O consumo de tempo da função
insercao()é, no melhor caso, proporcional a \(\mathtt{n}\), em que \(\mathtt{n}\) é o número de elementos na listav.
Vejamos alguns resultados experimentais envolvendo listas aleatórias, crescentes e decrescentes. Todos os tempos estão em segundos.
A coluna com os consumos de tempo para ordenar listas crescentes mostra que os tempos dobram a medida que o número de elementos n da lista dobra.
Esse é um sintoma de algoritmo que consomem tempo proporcional a \(\mathtt{n}\).
A coluna com os consumos de tempo para ordenar lista aleatórias mostram que os tempos aproximadamente quadruplicam a medida que o número \(\mathtt{n}\) de elementos da lista dobra. Essa é a características de algoritmo que consomem tempo proporcional a \(\mathtt{n^2}\).
As animações abaixo mostram a ordenação por inserção trabalhando com listas crescentes e decrescentes.
Revisita ao MDC#
Depois do que andamos vendo sobre análise de algoritmos vamos revisitar o problema pelo qual já passamos algumas vezes neste tesnto sendo que a última foi na seção Máximo divisor comum e Euclides:
Problema (máximo divisor comum): Dados dois números inteiros não-negativos
aeb, encontrar o máximo divisor comum deaeb.
O máximo divisor comum de \(\mathtt{a}\) e \(\mathtt{b}\), denotado por \(\mathtt{mdc(a,b)}\), é o maior inteiro positivo que é divisor comum de \(\mathtt{a}\) e \(\mathtt{b}\).
Por exemplo, o maior divisor comum de 12 e 20 é 4 pois 4 divide 12 e divide 20 e não há número inteiro maior que 4 que divida ambos, 12 e 20.
Vamos investigar a eficiência de três funções que resolvem o problema do máximo divisor comum. 🕵🏾
Uma função que estará sob nossa lente de aumento 🔎 será a euclideR() da seção Máximo divisor comum e Euclides.
def euclidesR(a, b):
"""(int, int) -> int
RECEBE dois inteiros a e b.
RETORNA mdc(a, b); se a = 0 = b retorna 0 para indicar erro.
PRÉ-CONDIÇÃO: a >= 0, b >=0
"""
if b == 0: return a
return euclidesR(b, a % b)
A segunda será a math.gcd() da biblioteca math do Python.
In [1]: import math
In [2]: math.gcd(12, 20)
Out[2]: 4
In [3]: math.gcd(539439, 2728)
Out[3]: 1
In [4]: math.gcd(3447882627912, 17436306624)
Out[4]: 6391608
Finalmente a terceira será a seguinte função mdc_tt()
def mdc_tt(a, b)
"""(int, int) -> int
RECEBE dois inteiros a e b.
RETORNA o mdc de a e b.
PRÉ-CONDIÇÃO: a > 0 e b > 0.
"""
0 d = min(a, b)
1 while a % d != 0 or b % d != 0:
2 d -= 1
3 return d
Os números nas linhas não fazem parte do código se só servem para fazermos referência às linhas.
Suponha \(\mathtt{d = min(a,b)}\).
A função mdc_tt() simplemente percorre os inteiros \(\mathtt{d}, \mathtt{d-1}, \mathtt{d-2}, \ldots\) a procura do \(\mathtt{mdc(a,b)}\).
Devido a esse caráter de busca sequência pelo \(\mathtt{mdc(a,b)}\) é que a função tem o sufixo tt de testa tudo.
Verifiquemos que a função mdc_tt() de fato faz o que promete. 🤨
Eis algumas das relações invariantes da função mdc_tt().
No início da linha 1 vale que:
(i0) \(\mathtt{1 \leq d \leq \min(a, b)}\), e
(i1) \(\mathtt{a \% t \neq 0}\) ou \(\mathtt{b \% t \neq 0}\) para todo \(\mathtt{t > d}\).
A invariante (i2) a seguir garante que (i0) e (i1) valem no início da próxima iteração com d-1 no papel de d.
No início da linha 2 vale que:
(i2) \(\mathtt{a \% d \neq 0}\) ou \(\mathtt{b \% d \neq 0}\).
Devido a relação (i2) é evidente, está na cara 🧑🏿🦰, que no início da linha 3, antes do return d vale que:
(i3) \(\mathtt{a \% d = 0}\) e \(\mathtt{b \% d = 0}\).
Como (i1) vale na linha 1, então também vale na linha 3.
Assim, nenhum número inteiro maior que o valor d a ser retornado divide a e b.
Portanto, o valor retornado pela função é de fato o maior dos divisores de \(\mathtt{a}\) e \(\mathtt{b}\), é o legítimo \(\mathtt{mdc(a,b)}\).
Invariantes são assim mesmo. 👍🏾
A validade inicial de umas, junto com trabalho feito pelo código, servem para confirmar a validade das relações em cada iteração. ఠ_ఠ
A correção da função ou algoritmo é muitas vezes consequência evidente da validade das relações.
Bem, passemos ao consumo de tempo de mdc_tt().
Quanto mais iterações do while.. são executdas, maior deve ser o consumo de tempo da função.
Faz sentido?! ¯\_(ツ)_/¯
Portanto é natural nos perguntarmos
Quantas iterações do
while...faz a funçãomdc()?
Essa pergunta é essencialmente a mesma que a questão
Quantas vezes o comando
d -= 1é executado?
A resposta a essa pergunta depende claramente dos valores de \(\mathtt{a}\) e \(\mathtt{b}\). 🤔
Se o \(\mathtt{mdc(a, b)}\) é \(\mathtt{\min(a,b)}\), valor inicial de d na linha 0, então o consumo de tempo é constante, independe de quão grandes são os valores de \(\mathtt{a}\) ou de \(\mathtt{b}\).
Esse é o melhor caso para mdc().
É quando a função trabalha menos. 😄 🤨
Já o pior caso ocorre quando \(\mathtt{a}\) e \(\mathtt{b}\) são relativamente primos ou coprimos.
Nesse caso o \(\mathtt{mdc(a, b)}\) é 1 e a linha 2 com o seu d -= 1 será executada com d tendo os valores min(a,b), min(a,b)-1, min(a,b)-2,…, 3, e 2.
Por exemplo, \(317811\) e \(514229\) são relativamente primos e a mdc_tt(317811, 514229) executará \(317811-1\) iterações do while...,
pois \(\mathtt{mdc(317811, 514229) = 1}\).
Neste caso, costumamos dizer que o consumo de tempo do algoritmo, no pior caso, é proporcional a \(\mathtt{\min(a, b)}\), ou ainda, que o consumo de tempo do algoritmo é da ordem de \(\mathtt{\min(a, b)}\). A abreviatura de ordem blá é \({\textup{O}(\mbox{blá})}\). Daqui a pouco conversaremos sobre essa tal de ordem de uma maneira um pouco mais precisa.
Conclusão: No pior caso, o consumo de tempo da função
mdc_tt()é proporcional a \(\mathtt{\min(a, b)}\).
Na pratica isso significa que se o valor de \(\mathtt{\min(a, b)}\) dobrar, então o tempo gasto pela função mdc_tt() pode, no pior caso, se formos azarados, dobrar. (҂◡_◡)
Vamos fazer um teste de resistência com a função mdc_tt() testando-a para valores de \(\mathtt{a}\) e \(\mathtt{b}\) que são relativamente primos.
Esses valores fazem com que mdc_tt() trabalhe muito.
Aproveitamos, para exibir resultados com os tempos gastos de outras duas funções além de mdc_tt():
math.gcd()da bibliotecamathdo Python; eeuclidesR()nosso algoritmo de Euclides caseiro.
Na tabela os tempos estão todos em segundos. Nem precisava dizer, mas na tabela os valores \(\mathtt{0.00}\) não são zeros de verdade. Algum tempo a função deve ter gastado para fazer o seu serviço. Esses \(\mathtt{0.00}\) indicam apenas que o tempo gasto foi muito pequeno. No caso, muito pequeno é qualquer coisa menor que \(\mathtt{0.005}\).
Examinemos um pouco a tabela. 🧐
Vemos que quando o valor de \(\mathtt{min(a,b)}\) foi de \(14930352\) para \(24157817\) o tempo gasto passou de \(1.12\) para \(1.81\).
Assim, quando o valor do \(\mathtt{min(a,b)}\) cresceu de aproximademente \(1.61\) vezes (\(14930352 \times 1.61 \approx 24037866\)), o tempo gasto também cresceu de aproximadamente \(1.61\) vezes, foi de \(1.12\) para \(1.81\) (\(1.12 \times 1.61 \approx 1.80\)).
Para outras outros pares de linhas vemos que um fenômeno semelhante se verifica!
Vejamos que quando \(\mathtt{min(a,b)}\) foi de \(3524578\) para \(102334155\), uma aumento de aproximadamente \(29\) vezes (\(3524578 \times 29 = 102212762\)), o tempo gasto saltou de \(0.26\) para \(7.78\) (\(0.26 \times 29 = 7.54\)).
Faz sentido, não?! ¯\_(ツ)_/¯
É esse o efeito do consumo de tempo ser proporcional a \(\mathtt{min(a,b)}\). 👍🏿
Agora, a pergunta que não quer calar é
Pergunta: Por que o tempo gasto por
euclideR()é tão menor que o demdc_tt()? 😕
Na próxima seção iremos dissecar a função euclideR() para respondermos a essa questão e entendermos o que está acontecendo. 😄
⚠️ Se trata da ideia, não se trata do computador.
A rigor deveríamos dizer qual o computador, com quantos núcleos, qual a versão do Python,…, utilizamos para obter esses tempos.
Para nós essa informação é irrelevante pois não estamos interessados no tempo gasto, poderíamos estar. 😯
Estamos interessados em determinar a velocidade que o tempo gasto cresce a medida que o trabalho que a função faz cresce.
Assim, no seu computador você pode e deve obter valores diferentes para os tempos gastos.
No entanto, a velocidade de crescimento do tempo em função do trabalho realizado pela função será aproximadamente o mesmo.
Essa velocidade depende do algoritmo, da ideia que a função implementa, e não do computador. 🙄
Brinque com o cronômetro abaixo no Trinket ou baixe tudo para o seu computador.
Esforço de Euclides#
Nesta seção vamos desvendar a mágica 🪄 do Euclides para seu algoritmo ser tão mais rápido que mdc_tt(), como constatamos nos experimentos no final da última seção.
Consideremos a função recursiva euclidesR() que implementa a ideia do Euclides.
Como discutimos na seção Máximo divisor comum e Euclides, o coração da ideia do Euclides e relação de recorrência:
O efeito dessa relação de recorrência pode ser visto no rastro de euclidesR(372, 162) que retorna \(\mathtt{6 = mdc(372, 162)}\).
euclidesR(372,162)
euclidesR(162,48)
euclidesR(48,18)
euclidesR(18,12)
euclidesR(12,6)
euclidesR(6,0) = 6
euclidesR(12,6) = 6
euclidesR(18,12) = 6
euclidesR(48,18) = 6
euclidesR(162,48) = 6
euclidesR(372,162) = 6
Simulando com papel e lápis o trabalho feito por ``euclidesR()` chegamos a tabela
Na linha inferior os valores \(\mathtt{48, 18, 12, 6, 0}\) são os restos das divisões.
Na linha superior os valores \(\mathtt{2, 3, 2, 1, 2}\) são os quocientes das divisões.
Por exemplo, logo no ínicio da tabela vemos \(\mathtt{18}\) que é \(\mathtt{372\%162}\) é vemos \(\mathtt{2}\) que é \(\mathtt{372 // 162}\).
A bem da verdade, para euclidesR(), os vamos dos quocientes são irrelevantes, não são usados.
Vamos examinar a função euclidesR() a fim de estimarmos o seu consumo de tempo.
Suponha que euclidesR() faz \(\mathtt{k}\) chamadas recursivas para determinar \(\mathtt{mdc(a, b)}\).
Nosso objetivo é determinar o valor de \(\mathtt{k}\) em termos de \(\mathtt{a}\) e \(\mathtt{b}\).
Isso é semelhante ao que fizemos quando investigamos a função mdc_tt() para limitarmos o número de execuções de d -= 1 em termos de \(\mathtt{a}\) e \(\mathtt{b}\).
Por conveniência suponha que \(\mathtt{a \geq b > 0}\). Podemos visualizar essa chamadas recursivas com papel e lápis escrevendo:
Em que os \(\mathtt{q_i}\) s e os \(mathtt{r_i}\) s são os quocientes e restos das divisões, respectivamente.
Dessa forma
são os valores dos argumentos no início de cada uma das chamadas da função euclideR().
Por exemplo, para \(\mathtt{a=514229}\) e \(\mathtt{b=317811}\) temos que
euclidesR(317811,514229)
euclidesR(514229,317811)
euclidesR(317811,196418)
euclidesR(196418,121393)
euclidesR(121393,75025)
euclidesR(75025,46368)
euclidesR(46368,28657)
euclidesR(28657,17711)
euclidesR(17711,10946)
euclidesR(10946,6765)
euclidesR(6765,4181)
euclidesR(4181,2584)
euclidesR(2584,1597)
euclidesR(1597,987)
euclidesR(987,610)
euclidesR(610,377)
euclidesR(377,233)
euclidesR(233,144)
euclidesR(144,89)
euclidesR(89,55)
euclidesR(55,34)
euclidesR(34,21)
euclidesR(21,13)
euclidesR(13,8)
euclidesR(8,5)
euclidesR(5,3)
euclidesR(3,2)
euclidesR(2,1)
euclidesR(1,0) = 1
[...]
euclidesR(317811,514229) = 1
Notemos ainda que para inteiros \(\mathtt{m}\) e \(\mathtt{n}\) com \(\mathtt{m \geq n >0}\) vale que
Desta forma temos que
Com isso vemos que depois de 2 aplicações sucessivas de duas chamadas recursivas, o valor do primeiro argumento, o \(\mathtt{a}\), é reduzido a menos da metade.
Suponhamos que \(\mathtt{t}\) é o número inteiro tal que
Da primeira desigualdade temos que
em que \(\mathtt{\lg a}\) é o logaritmo de \(\mathtt{a}\) na base 2.
Da desigualde estrita, concluímos que
Logo, o número \(\mathtt{k}\) de divisões, chamadas recursivas, é não superior a
Para o exemplo acima, em que \(\mathtt{a=514229}\) e \(\mathtt{b= 317811}\), temos que
e o número de chamadas recursivas feitas por euclidesR(514229,317811) é 27.
Resumindo, a quantidade de tempo consumida pelo algoritmo de Euclides é, no pior caso, proporcional a \(\mathtt{\lg a}\).
Notemos que se \(\mathtt{a < b}\) então a chamada euclides(a, b) faz apenas uma chamada recursiva a mais que a chamada euclides(a, b).
Portanto chegamos a nossa
Conclusão: No pior caso, o consumo de tempo de
euclideR(a, b)é proporcional a \(\mathtt{\lg d}\), em que \(\mathtt{d = \min(a,b)}\).
Este desempenho é significativamente melhor que o desempenho do algoritmo café com leite implementada na função mdc_tt()
já que a função :math:f(d) = \lg d cresce muito mais lentamente que a função \(\mathtt{g(d) = d}\).
O consumo de tempo \(\mathtt{\lg d}\) significa se a função euclidesR(a, b) gasta \(\mathtt{t}\) unidades de tempo, então para que a chamada
euclidesR(m, n) gaste \(\mathtt{2t}\) unidades de tempo é necessário, mas não suficiente ⚠️,
que \(\mathtt{\min(m,n)}\) seja cerca de \(\mathtt{d^2}\), em que \(\mathtt{d = \min(a,b)}\). 😮
Podemos verificar que o tempo gasto pela versão recursiva euclidesR() do algoritmo de Euclides gasta aproximadamente o mesmo tempo que a sua versão iterativa euclidesI().
Com tudo que vimos, desvendamos o mistério da eficiência absurda da ideia do Euclides. 😄
Oh#
Para expressar o consumo de tempo ou de espaço de funções, métodos, programas e algoritmos é comum utilizarmos a notação assintótica. Ela expressa os recursos utilizados no limite, a medida que a quantidade de dados cresce. A quantidade de dados é chamada tamanho do problema. Em algoritmos de busca e de ordenação é de se esperar que o consumo de tempo dependa do número \(\mathtt{n}\) de elementos na lista sob consideração. Veja, na página TimeComplexity, como são registrados os tempos médios e os tempos no pior caso gastos por métodos de várias classes nativas do Python.
Observando a tabela abaixo de \(\mathtt{(3/2)n^2 + (7/2)n -4}\) versus \(\mathtt{(3/2)n^2}\) vemos que a medida que \(\mathtt{n}\) cresce os termos de menor ordem colaboram poucou para o valor final. No final das contas \(\mathtt{(3/2)n^2}\) domina amplamente todos os demais termos. \(\mathtt{(3/2)n^2}\) é \(\mathtt{\textup{O}(n^2)}\)
Para sentir como o número de operações impacta no consumo de tempo de um algoritmo, veja a tabela a seguir que foi copiada do livro Projeto de Algoritmos de Michael T. Goodrich e Roberto Tamassia, Bookman. A tabela supõe que cada operação consome \(1\) microsegundo, ou seja, \(1\mu\) s.
A tabela mostra que um algoritmo que gasta cerca de \(400n \; \mu\) segundos resolve em 1 segundo um problema de tamanho até \(\mathtt{n=2500}\), em 1 minuto resolve um problema de tamanho \(\mathtt{n=150}\) mil e em 1 hora de tamanho \(\mathtt{n=9}\) milhões.
Olhando as outras linhas vemos que, no final das contas, para analisar o desempenho para um problema grande o que mais importa é o termo que cresce mais rapidamente e que acaba dominando os demais. A notação assintótica \(\textup{O}\)-grande procura capturar essas ideias.
Sejam \(\mathtt{T(n)}\) e \(\mathtt{f(n)}\) funções dos inteiros nos reais. Dizemos que \(\mathtt{T(n)}\) é \(\mathtt{\textup{O}(f(n))}\) se existem constantes positivas \(\mathtt{c}\) e \(\mathtt{n_0}\) tais que
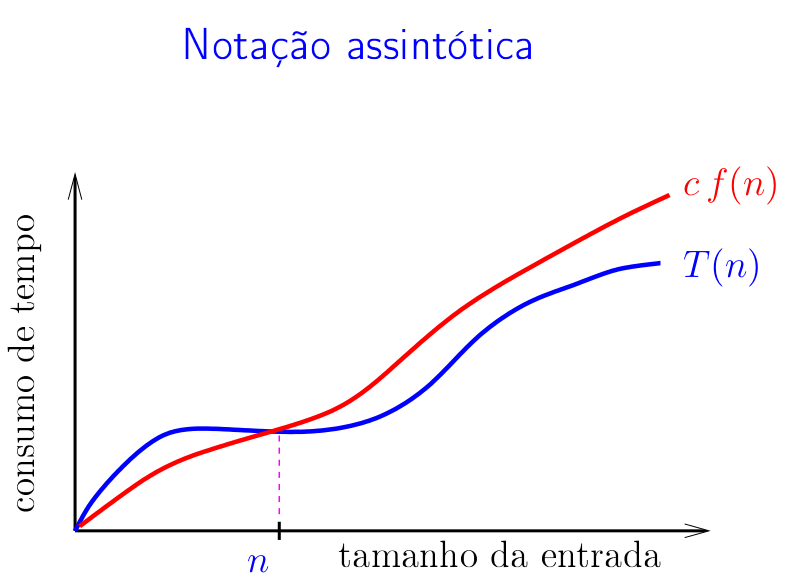
De uma maneira mais intuitiva, \(\mathtt{T(n)}\) é \(\mathtt{\textup{O}(f(n))}\) se existe \(\mathtt{c}>0\) tal que
Vejam o crescimento de algumas funções conhecidas.
Algumas classes \(\textup{O}\) mais comuns, mais famosas, recebem nomes.
Temos, portanto, que o consumo de tempo da função:
hanoi()é \(\mathtt{\textup{O}(2^n)}\), exponencial, em que \(\mathtt{n}\) é o número de discos do quebra-cabeça;sequencial()que implementa a busca sequencial é \(\mathtt{\textup{O}(n)}\), linear, desta vez \(\mathtt{n}\) é o tamanho da lista que será percorrida;busca_bin()que faz busca binária é \(\mathtt{\textup{O}(\lg n)}\), logarítmico, mais uma vez \(\mathtt{n}\) é o tamanho da lista que será percorrida;insercao()que faz ordenação por inserção é \(\mathtt{\textup{O}(n^2)}\), quadrático, aqui \(\mathtt{n}\) é o número de elementos na lista a ser ordenada ;mdc_tt()para determinar o maior divisor comum de um par de números inteiros \(\mathtt{a}\) e \(\mathtt{b}\) é \(\mathtt{\textup{O}(d)}\), linear; em que \(mathtt{d = \min(a,b)}\);eunclideR()para encontra o maior divisor comum de um par de números inteiros \(\mathtt{a}\) e \(\mathtt{b}\) é \(\mathtt{\textup{O}(\lg d)}\), logarítmico; novamente \(mathtt{d = \min(a,b)}\).
A análise de consumo de tempo não são apenas um bando de contas seguidas de símbolos! Os valores obtidos têm impacto inegável, estão nas estranhas, do tempo gasto pelas funções que implementam os algoritmos. 😮
Dicionários ordenados#
Como exercício faremos uma classe DicioB implementando um dicionário em que as chaves são mantidas em ordem crescente.
Esse é um trabalho para a parceria entre busca binária e ordenação por inserção.
Para que as chaves de um objeto da classe DicioB sejam mantidas em ordem, diferentemente do que ocorreu com a classe Dicio,
as chaves não podem ser de tipos quaisquer.
Se dB é um objeto DicioB e chave1 e chave2 são duas das chaves em dB, então deve ser possível fazermos
comparações como: classe1 < classe2, classe1 <= classe2, classe1 > classe2, classe1 >= classe2. Por exemplo, as chaves de dB podem ser da classe nativa str
ou da classe nativa int, mas não de ambas, já que comparações como 5 < 'xx' resultam em erro
Aparte a ordenação das chaves, um dicionário da classe DicioB é semelhante a um dicionário da classe Dicio.
Ao ser criado, um objeto DicioB representa um dicionário vazio.
In [2]: dB = DicioB()
In [3]: print(dB) # note a linha vazia a seguir
In [4]:
Como sempre, a string utilizada quando escrevemos print(dB) é aquela retornada pelo método mágico __str__()
que retorna uma string que representa dB.
Um item, ou seja, par (chave, valor) pode ser inserido em um dicionário de duas formas diferentes.
Uma delas é usando o método put():
In [4]: dB.put('fracassei', 3)
In [5]: dB.put('em', 1)
In [6]: dB.put('tudo', 1)
In [7]: print(dB)
em: 1
fracassei: 3
tudo: 1
Note que as chaves estão em ordem crescente: `` ‘em’ < ‘fracassei’ < ‘tudo’ ``
A outra maneira é semelhante a mudarmos o valor de um elemento de uma lista.
Esse comportamento é de responsabilidade do (já visto) método mágico __setitem__().
In [8]: dB['o'] = 2
In [9]: dB['que'] = 3
In [10]: dB['tentei'] = 4
In [11]: print(dB)
em: 1
fracassei: 3
o: 2
que: 3
tentei: 4
tudo: 1
Note que as chaves estão em ordem crescente: `` ‘em’ < ‘fracassei’ < ‘o’ < ‘que’ < ‘tentei’ < ‘tudo’ ``
Podemos atualizar o valor associado a uma chave procedendo da mesma forma que inserimos um item no dicionário.
In [12]: dB.put('o', 2)
In [13]: dB['que'] = 1
In [14]: dB['tentei'] = 5
In [15]: print(dB)
em: 1
fracassei: 3
o: 2
que: 1
tentei: 5
tudo: 1
Para obtermos, ou, como dizem, buscar o valor associado a uma chave usamos o método get().
In [16]: dB.get('fracassei')
Out[16]: 3
In [17]: dB.get('em')
Out[17]: 1
In [18]: dB.get('tudo')
Out[18]: 1
Podemos ainda manipular dicionários como listas.
Essa característica é de responsabilidade do conhecido método mágico __getitem__().
In [19]: dB['o']
Out[19]: 2
In [20]: dB['que']
Out[20]: 1
In [21]: dB['tentei']
Out[21]: 5
Esse métodos retornam None se a chave não estiver no dicionário:
In [27]: print(dB.get('vida'))
None
In [28]: print(dB['vida'])
None
Tenha em mente que as chaves de dicionários ordenados devem ser comparáveis.
Para sabermos se uma chave pertence a um dicionário podemos utilizar o operador in, de maneira semelhante ao que fazemos
com objetos da classe list. Essa é uma característica patrocinada pelo método mágico __contains__():
In [29]: 'tentei' in dB
Out[29]: True
In [30]: '1' in dB
Out[30]: False
In [31]: 1 in dB
Out[31]: True
In [32]: 5 in dB
Out[32]: False
No que diz respeito a comandos de repetição, com o patrocínio do método mágico __iter__(),
podemos proceder da seguinte maneira:
In [36]: for chave in dB: print(f"{chave}: {dB[chave]}")
em: 1
fracassei: 3
o: 2
que: 1
tentei: 5
tudo: 1
Note que as chaves estão em ordem crescente.
Objetos da classe DicioB têm ainda três outros métodos que podem ser bem úteis, inclusive para testarmos nossas implementações.
Esses métodos são:
keys()que retorna a lista de chaves do dicionário;values()que retorna a lista de valores do dicionário; eitems()que retorna a lista dos itens do dicionário.
In [22]: dB.keys()
Out[22]: ['em', 'fracassei', 'o', 'que', 'tentei', 'tudo']
In [23]: dB.values()
Out[23]: [1, 3, 2, 1, 5, 1]
In [24]: dB.items()
Out[24]: [('em', 1), ('fracassei', 3), ('o', 2), ('que', 1), ('tentei', 5), ('tudo', 1)]
Note que as chaves estão em ordem crescente.
Implementação#
Passaremos agora a implementação da classe DicioB.
Você deverá implementar métodos que fazem parte do motor da classe DicioB: o método administrativo indice() e os métodos put() e get()
que podem se apoiar em indice() para fazerem os seus serviços.
O arquivo main.py tem uma função main() no final que é uma unidade de teste para sua classe.
Testes#
Para testar a sua implementação da classe DicioB você pode utilizar a função main() a seguir.
A saída esperada produzida pela função main() está mais adiante.
def main():
'''
Unidade de teste para a classe DicioB
'''
print("Testes para a classe DicioB")
print("--------------------------\n")
# __init__() e __str__()
print("crie um dicionário vazio")
dB = DicioB()
print(f"dB:\n{dB}")
pause() # aprecie a paisagem
# put()
print("\nteste put()")
dB.put('fracassei', 3)
dB.put('em', 1)
dB.put('tudo', 1)
print(f"dB:\n{dB}")
pause() # aprecie a paisagem
# __setitem__()
print("\nteste __setitem__()")
dB['o'] = 2
dB['que'] = 3
dB['tentei'] = 4
print(f"dB:\n{dB}")
pause() # aprecie a paisagem
# put() e __setitem__()
print("\nteste put() e __setitem__()")
dB.put('o', 2)
dB['que'] = 1
dB['tentei'] = 5
print(f"dB:\n{dB}")
pause() # aprecie a paisagem
# get()
print("\nteste get()")
print(f"dB.get('fracassei')={dB.get('fracassei')}")
print(f"dB.get('em')={dB.get('em')}")
print(f"dB.get('tudo')={dB.get('tudo')}\n")
pause() # aprecie a paisagem
# __getitem__()
print("\nteste __getitem__()")
print(f"dB['o']={dB['o']}")
print(f"dB['que']={dB['que']}")
print(f"dB['tentei']={dB['tentei']}")
print(f"dB.get('vida')={dB.get('vida')}")
print(f"dB['vida']={dB['vida']}\n")
pause() # aprecie a paisagem
# mais __setitem__()
print("\nmais teste __setitem__(): chaves devem ser comparáveis por <, <=,...")
dB['na'] = 1
dB['vida'] = 1
print(f"dB:\n{dB}")
pause() # aprecie a paisagem
# teste __contains__()
print("\nteste __contains__()")
print(f"'tentei' in dB={'tentei' in dB}")
print(f"'1' in dB={'1' in dB}")
print(f"1 in d={1 in dB}")
print(f"5 in d={5 in dB}\n")
pause() # aprecie a paisagem
# teste __iter__()
print("\nteste __iter__(): usado para clonar d")
clone = DicioB()
for chave in dB: clone[chave] = dB[chave]
print(f"clone:\n{clone}")
pause() # aprecie a paisagem
# teste __len__()
print("\nteste __len__()")
print(f"len(dB)={len(dB)}")
print(f"len(clone)={len(clone)}")
dicio_vazio = DicioB()
print(f"len(dicio_vazio)={len(dicio_vazio)}\n")
pause() # aprecie a paisagem
# teste keys(), values() e items()
print("\nteste keys(), values() e items()")
print(f"clone.keys()={clone.keys()}")
print(f"clone.values()={clone.values()}")
print(f"clone.items()={clone.items()}\n")
pause() # aprecie a paisagem
print("FIM")
crie um dicionário vazio
dB:
Tecle ENTER para continuar:
teste put()
dB:
em: 1
fracassei: 3
tudo: 1
Tecle ENTER para continuar:
teste __setitem__()
dB:
em: 1
fracassei: 3
o: 2
que: 3
tentei: 4
tudo: 1
Tecle ENTER para continuar:
teste put() e __setitem__()
dB:
em: 1
fracassei: 3
o: 2
que: 1
tentei: 5
tudo: 1
Tecle ENTER para continuar:
teste get()
dB.get('fracassei')=3
dB.get('em')=1
dB.get('tudo')=1
Tecle ENTER para continuar:
teste __getitem__()
dB['o']=2
dB['que']=1
dB['tentei']=5
dB.get('vida')=None
dB['vida']=None
Tecle ENTER para continuar:
mais teste __setitem__(): chaves devem ser comparáveis por <, <=,...
dB:
em: 1
fracassei: 3
na: 1
o: 2
que: 1
tentei: 5
tudo: 1
vida: 1
Tecle ENTER para continuar:
teste __contains__()
'tentei' in dB=True
'1' in dB=False
1 in d=False
5 in d=False
Tecle ENTER para continuar:
teste __iter__(): usado para clonar d
clone:
em: 1
fracassei: 3
na: 1
o: 2
que: 1
tentei: 5
tudo: 1
vida: 1
Tecle ENTER para continuar:
teste __len__()
len(dB)=8
len(clone)=8
len(dicio_vazio)=0
Tecle ENTER para continuar:
teste keys(), values() e items()
clone.keys()=['em', 'fracassei', 'na', 'o', 'que', 'tentei', 'tudo', 'vida']
clone.values()=[1, 3, 1, 2, 1, 5, 1, 1]
clone.items()=[('em', 1), ('fracassei', 3), ('na', 1), ('o', 2), ('que', 1), ('tentei', 5), ('tudo', 1), ('vida', 1)]
Tecle ENTER para continuar:
FIM
Paisagens vistas#
Exercícios#
Escreva uma função
busca_binaria(v, x, e, d)que recebe uma lista crescentev[e:d]e um objetoxe retorna um índicejemrange(e,d)tal que, após a inserção dexna posiçãov[j+1], a listav[e:d+1]será crescente. A sua função deverá ser uma adaptação da funçãobusca_bin(). Uma função com a especificação da dessabusca_binaria()é um dos motores de uma versão do algoritmo por inserção.A versão da busca binária a seguir tem alguns problemas. Quais são? Como podemos repará-los?
def busca_binariaR(v, x): n = len(v) if n == 0: return None m = n // 2 if v[m] == x: return m if v[m] < x: return busca_binariaR(v[m+1:],x) return busca_binariaR(v[:m], x)
O que é …#
Aqui vai o resumo do significado de alguns termos usados neste capítulo. 🤓
- Consumo de tempo constante#
Dizemos que uma função, um programa, ou um trecho de código consome tempo constante quando o tempo gasto para executá-lo independe dos dados sendo manipulados.
- Análise de pior caso#
A análise de pior caso considere o maior tempo ou espaço gasto por uma função, um programa, ou um trecho de código em função do a entrada
- Tamanho de um objeto#
Tipicamente é o número de bytes para representá-lo. Esse número depende da escolha da representação.
- Tamanho de um inteiro#
Tipicamente é o número de dígitos usados para representá-lo. O tamanho do inteiro
1234é4. Esse número depende da escolha da representação. Na base 2 escrevemos o número decimal1234como11010010que usa8dígitos binários.- Tamanho de uma lista#
Utilizamos o número de componentes da lista como sendo seu tamanho. O tamanho da lista
[1, 2, 3]élen([1,2,3]) = 3e da lista[[1],[1,2],[1,2,3]]élen([1]) + len([1,2]) + len([1,2,3]) = 6.- Tamanho de um objeto#
Número de símbolos usados para representar o objeto. Essa medida depende do conjunto de símbolos. Se consideramos os símbolos que aparecem no teclado do computador ⌨️, o tamanho do inteiro
1234é4, da string"mac0122"é 7. O tamanho de um objeto complexo é a soma dos tamanhos de seu componentes.
Para saber mais#
Busca em vetor ordenado de Projeto de Algoritmos de Paulo Feofiloff.
Ordenação: algoritmos elementares de Projeto de Algoritmos de Paulo Feofiloff.
A Busca Binária de Resolução de Problemas com Algoritmos e Estruturas de Dados usando Python de Brad Miller e David Ranum.
A Ordenação Por Inserção de Resolução de Problemas com Algoritmos e Estruturas de Dados usando Python de Brad Miller e David Ranum.
Notação O de Resolução de Problemas com Algoritmos e Estruturas de Dados usando Python de Brad Miller e David Ranum.
Dicionários de Como Pensar Como um Cientista da Computação de Brad Miller e David Ranum.
Analysis of Algorithms de Introduction to Programming in Python. de Robert Sedgewick, Kevin Wayne e Robert Dondero.